Do You Need llms.txt?
A lot of teams heard about llms.txt and assumed it was the missing step for AI visibility. In practice, it helps only after the basics are already working: crawl access, strong pages, and a site structure worth guiding.
- llms.txt
- AI SEO
- Technical SEO
- AEO
Do You Actually Need an llms.txt File?
For most sites, no. The honest answer is that llms.txt is a niche file with a narrow use case. Three independent studies in the last year found no measurable AI-search benefit. Publish it if you ship developer docs read by coding agents. Otherwise, fix your basics first and treat the file as cheap optionality.
Key Takeaways
llms.txtwas designed for inference-time context, not crawler access or AI-search ranking (llmstxt.org, 2024).- Ahrefs found 97% of valid
llms.txtfiles received zero requests in May 2026 across 137,210 domains (Ahrefs, 2026).- Adoption sits near 10%, and there is no clear link to AI citations across roughly 300,000 domains (Search Engine Journal, 2025).
- Best fit: documentation sites whose content gets pulled into IDE and coding agents.
- Wrong reason to publish: chasing AI-search visibility. Use the AI Readiness Checker instead.
This post is a decision guide, not a tutorial. The goal is to tell you which branch you fall on: publish now, publish for a specific reason, or wait. We will walk the tree with real evidence and skip the hype.
What llms.txt Was Actually Designed To Do
llms.txt is an inference-time context file, not a crawler-control file. Jeremy Howard of Answer.AI proposed it on September 3, 2024, as a curated, LLM-friendly map a model could read while it works (llmstxt.org, 2024). The reason was simple: context windows are too small to hold a full website.
That origin matters because it explains every wrong assumption people make. llms.txt is not robots.txt. It does not grant or deny access. It does not control training. It does not tell a search engine how to rank you. It is a markdown file that says “here are the pages worth reading, in priority order,” for a model that is already trying to use your site.
How it differs from robots.txt
robots.txt is a gate. It tells bots where they may go. llms.txt is a guide. It assumes a model already has access and wants help finding the good parts. Confusing the two leads teams to publish llms.txt while a stray robots.txt rule still blocks the crawlers they care about.
If you suspect that mix-up applies to you, that is a crawler-access problem, and it is the first thing the AI Readiness Checker flags.
Does llms.txt Help With AI Search Visibility?
No, not based on current evidence. Three separate datasets converge on the same result. SE Ranking analyzed about 300,000 domains and found no measurable relationship between having llms.txt and how often a domain gets cited in major LLM answers (Search Engine Journal, 2025). Removing the variable improved their model.
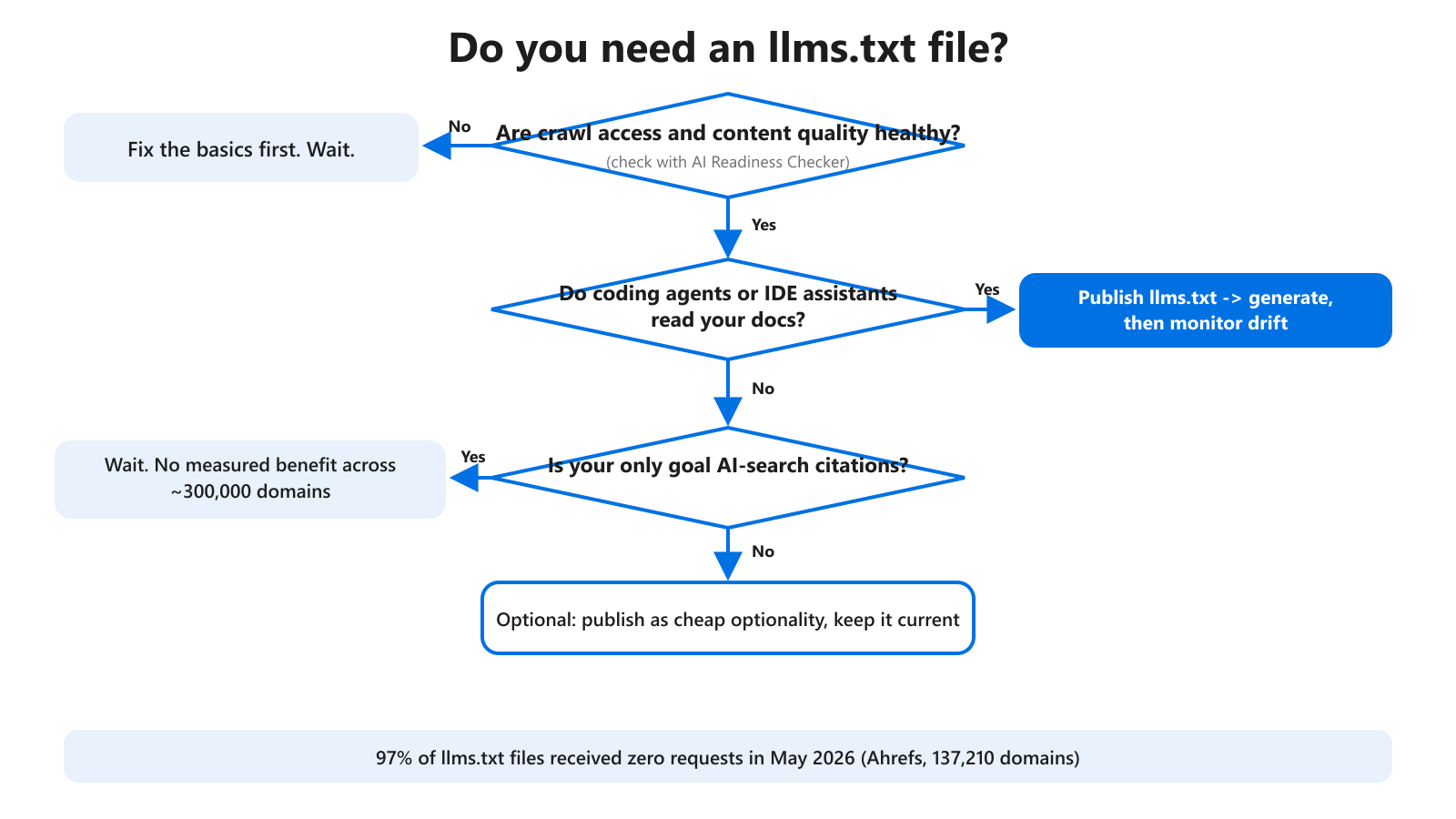
Figure 1: The decision tree. Fix the basics first, then branch on whether coding agents actually read your docs.
The other two studies measured behavior, not correlation. Ahrefs reviewed server logs for 137,210 domains and found 97% of valid llms.txt files got zero requests in May 2026 (Ahrefs, 2026). Otterly.AI ran a 90-day log experiment and saw the file catch roughly 0.1% of AI bot traffic, 84 of more than 62,100 visits (Otterly.AI, 2026).
Here is the part that surprises people. In the small slice of files Ahrefs saw fetched, most requests came from non-AI bots: SEO crawlers, audit tools, and general spiders, not the retrieval bots behind AI answers. So the file is rarely read, and when it is read, it is often not even an AI doing the reading.
Who Should Publish llms.txt Right Now?
Developer-tooling and documentation sites have the one credible use case. When a coding agent or IDE assistant pulls your docs at inference time, a clean llms.txt gives it a curated entry point. That is the branch where the file does real work, and the data backs it up. Among the AI fetches Ahrefs recorded, Anthropic’s Claude-Code agent was a leading requester (Ahrefs, 2026).
The split in the evidence is not “llms.txt works or it doesn’t.” It is “llms.txt works for one audience.” The sites getting value are the ones whose content is meant to be consumed programmatically: API references, SDK guides, integration docs. Anthropic, Stripe, Cloudflare, Vercel, and Supabase publish it for exactly that reason. None of them published it to win AI-search citations.
Signs you are in this branch
- You ship a public API, SDK, or developer documentation hub.
- Your users already work inside IDEs and coding agents.
- Your docs change in structured, predictable ways you can mirror in a file.
- You can keep the file current without it becoming a chore.
If that describes you, publishing is reasonable. Generate it with the LLMs.txt Generator + Validator and move on. The cost is low and the audience is real.
When Should You Wait Instead?
Wait when your reason for publishing is AI-search visibility, or when your site is unstable. The evidence shows no citation benefit, so publishing to chase rankings is effort spent on the wrong file. Worse, a llms.txt you cannot maintain becomes a liability: it points models at old URLs and de-emphasizes your newer, stronger pages.
In our experience auditing sites, the teams who regret publishing early are usually mid-migration or mid-restructure. They ship a tidy file in week one, change their information architecture in week three, and forget the file exists by month two. Now it is technical debt that quietly contradicts the sitemap.
Hold off if any of these are true
- Your real goal is more AI citations, not helping an agent already on your site.
- You are in the middle of a migration or a major content overhaul.
- Your URL structure shifts week to week.
- You do not yet know which pages deserve to be treated as canonical references.
In all of those cases, the file creates cleanup later. Spend the time on access and content instead. Run your key pages through the AI Readiness Checker and fix what it surfaces before you touch llms.txt.
Why Google Refuses To Use It
Google declines to read or act on llms.txt, and the reasoning is worth understanding. John Mueller argued the file cannot help AI systems tell sites apart during discovery, because every site can simply self-report being the best (Search Engine Journal, 2026). He compared its self-reported nature to the long-discredited keywords meta tag.
That is the structural problem with the file as a ranking signal. A claim you make about yourself, with no external verification, carries no weight in a competitive ranking decision. Mueller did acknowledge a narrow exception: automated systems already operating on a site can use it. That exception is exactly the developer-tooling branch above, and it is the only branch with signal.
So the picture is consistent across sources. The file helps a model that is already on your site and wants direction. It does not help you get discovered, ranked, or cited in the first place.
What Belongs In the File If You Do Publish?
Treat llms.txt as a curated reference list, not a sitemap dump. The best candidates are foundational guides, your strongest documentation hubs, and the canonical pages you genuinely want a model to quote. A noisy file that lists everything guides nothing, and it lets weak pages compete with your strong ones.
Use a simple filter for each candidate URL. Ask whether the page is canonical and stable, whether you would want an AI system to summarize it, and whether it is stronger than other pages on the same topic. If any answer is no, leave it out. That filter beats adding pages just because they exist.
Keep it honest after launch
Confirm the file is reachable, confirm the listed URLs are current, and compare it against your main sitemap. Then watch for drift as you publish and retire content. The LLMs.txt Drift Monitor handles that last part, which is where most well-intentioned files quietly decay.
FAQ
Is llms.txt the same as robots.txt?
No. robots.txt controls crawler access and tells bots where they may go. llms.txt is an inference-time guide for a model that already has access, pointing it to the pages worth reading (llmstxt.org, 2024). They solve different problems, and one cannot substitute for the other.
Will publishing llms.txt get me more AI citations?
There is no evidence it will. SE Ranking found no measurable link between the file and citation frequency across roughly 300,000 domains, and removing the variable improved their model (Search Engine Journal, 2025). Treat it as optionality, not a visibility lever.
Does anything actually read the file?
Rarely. Ahrefs found 97% of valid files received zero requests in May 2026, and most of the few that were fetched came from non-AI crawlers (Ahrefs, 2026). The clearest AI reader in the data was Anthropic’s Claude-Code agent, which fits the developer-docs use case.
How common is llms.txt today?
Uncommon. SE Ranking’s crawl found the file on only 10.13% of domains, meaning about nine in ten sites have not implemented it (Search Engine Journal, 2025). Low adoption is not a reason to rush. It reflects how narrow the real use case still is.
What should I fix before even considering it?
Crawler access and content quality. If AI bots cannot reach your pages, or your pages are thin and hard to summarize, llms.txt changes nothing. Confirm the fundamentals with the AI Readiness Checker first, then decide whether the file adds anything for your audience.
What To Do Next
Start with the basics, not the file. Run your key pages through the AI Readiness Checker to confirm crawlers can reach them and your content is structured well. If those fundamentals are healthy and you ship docs that coding agents read, generate the file with the LLMs.txt Generator + Validator and keep it honest with the LLMs.txt Drift Monitor.
If your real goal is visibility, the file is the wrong tool. Read How to Optimize Your Site for AI Citations and How to Check if AI Crawlers Can Access Your Site instead. Those two cover the work that actually moves the needle.