エージェント対応: サイトをエージェント Web 向けに整える方法
AI エージェントはページを読むだけの段階を過ぎました。ユーザーに代わってフライトを予約し、部品を発注し、チェックアウトを実行し、API にサインインします。適切なシグナルを公開したサイトは使われ、そうでないサイトは飛ばされます。新しい Agent Protocol Readiness Checker は、エージェントがいま探している正確なシグナルを URL からスキャンします。
- AIエージェント
- MCP
- エージェントコマース
- テクニカルSEO
エージェント Web に専用の監査が必要な理由
いまや、どんな人間よりも先にあなたのオリジンへ到達する新種の訪問者がいます。それは「行動するソフトウェア」です。Cloudflare は2025年に、ネットワーク全体の全 HTML リクエストのうち AI ボットによるトラフィックが4.2%を占めると計測しました(Cloudflare Radar 2025 Year in Review、2025年)。その割合が購入し、予約し、サインインしています。Agent Protocol Readiness Checker は、あなたのサイトがそれに応じられるかを監査します。
重要なポイント
- AI ボットはすでに Cloudflare のネットワーク上で HTML リクエストの約4.2%を占めており(Cloudflare Radar、2025年)、その割合は上昇を続けています。
- エージェントは HTML を解析する前に、
/.well-known/パス、コンテンツネゴシエーション、ボット認証鍵を確認します。- このチェッカーは、発見可能性、コンテンツアクセス、アイデンティティ、機能、コマースという5つのレイヤーを採点します。
- 初回実行のほとんどのサイトは10から30の間に収まります。狙いを定めた3つの修正で、通常は合格ラインまで到達します。
- 重みの大きいギャップから着手しましょう。Markdown ネゴシエーションとプロトコル検出だけでスコアの45%を占めます。
現代のエージェントが物事を進める順序を考えてみてください。人間のようにホームページを開いて上から順に読み始めることはありません。まず探りを入れます。サーバーにいくつかの鋭い質問を先に投げかけるのです。クリーンな Markdown を返すか、ツールマニフェストを公開しているか、署名付きリクエストを受け付けるか、決済を処理できるか。これらのプローブが失敗して初めて、生の HTML スクレイピングという、遅くて欠落の多い手段に後退します。
この探索的な振る舞いこそ、エージェント対応が独立した分野である理由です。SEO は Google の評価のされ方を調整します。Answer Engine Optimization はチャットアシスタントによる引用のされ方を調整します。エージェント対応が調整するのは別のもの、つまりソフトウェアがそもそもあなたと取引できるかどうかです。このチェッカーはコンテンツ監査ではなくプロトコル監査であり、エージェントがどのレイヤーで諦めるかをレイヤーごとに教えてくれます。
Agent Protocol Readiness Checker は何を計測するのか
このチェッカーは URL に対して20を超えるプローブを実行し、影響度で重み付けした5つの採点レイヤーにまとめます。プロトコル検出とエージェントコマースがそれぞれ採点の25%、コンテンツアクセシビリティが20%、発見可能性とボットアクセスがそれぞれ15%を占めます。各プローブは、生のサーバー証跡を添えて合格、警告、失敗のいずれかを返します。

図1: エージェントが評価する5つのレイヤーと、それぞれが最終グレードに占める重み。
レイヤー構造の要点は順序にあります。あなたの robots.txt を見つけられないエージェントは、Markdown を返すかどうかの問いにたどり着くことすらありません。コンテンツをクリーンに読み取れないエージェントが、ツールを公開しているかどうかを確認する手間をかけることはまずありません。失敗は下流へと連鎖するため、下位レイヤーがその上のすべてを左右します。
引用カプセル
Agent Protocol Readiness Checker は、20超のプローブにわたって重み付けされた5つのレイヤーを採点します。発見可能性とボットアクセスがそれぞれ15%、コンテンツアクセシビリティが20%、プロトコル検出とエージェントコマースがそれぞれ25%です。各プローブは生のサーバー証跡とともに合格、警告、失敗を返します。AI ボットはすでに HTML リクエストの4.2%を占めています(Cloudflare Radar、2025年)。
私たちがこれを作ったのは、既存のツールが間違った問いに答えているからです。ほとんどの監査は「Google はこのページを評価するか」を尋ねます。私たちが必要としたのは「人間を介さずに自律エージェントがこのオリジンを使えるか」を尋ねるものでした。この2つは同じサイトではありません。あるページが見事に評価されていても、予約エージェントにとっては行き止まりということがあり得ます。
エージェントはどのようにサイトを発見し読み取るのか
発見可能性とコンテンツアクセスは最初の2つのレイヤーであり、エージェントがそもそも動き始められるかどうかを決めます。エージェントはまず robots.txt を解決し、次にポインターを求めて Link レスポンスヘッダーを読み、それからコンテンツタイプをネゴシエートします。ほとんどのオリジンは Markdown ネゴシエーションで0点ですが、これは AI を介したトラフィックにとって労力対効果が最も高い唯一の修正です。
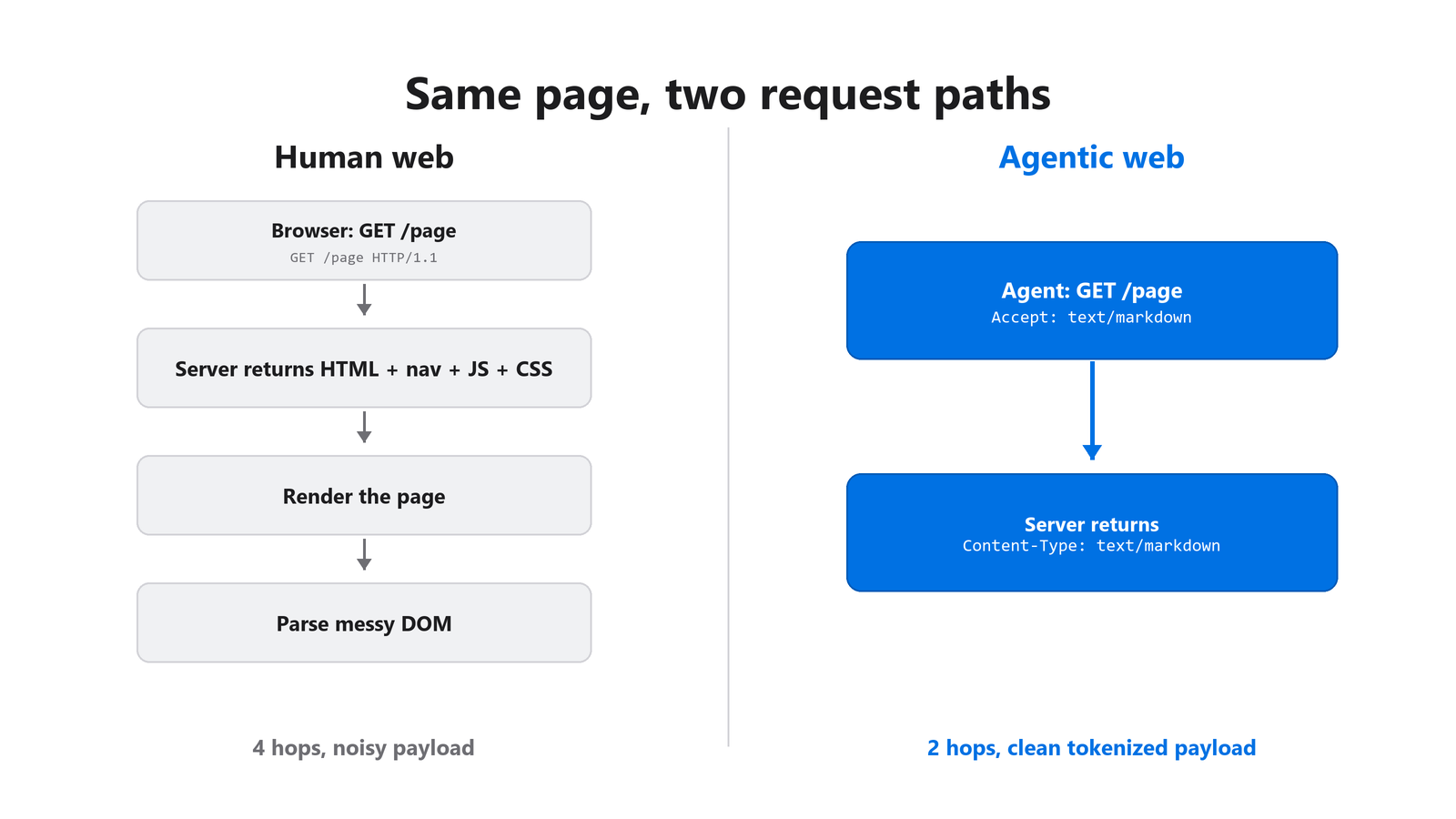
図2: 人間の Web はレンダリング済みの HTML を返す。エージェント Web はより少ない往復でネゴシエートされた Markdown を返す。
発見可能性: エージェントが最初に解決するファイル
3つのプレーンなファイルが下地を整えます。RFC 9309 に準拠した有効な robots.txt、その robots ファイルが Sitemap: 行で指し示すサイトマップ、そして /.well-known/ 配下のリソースを示唆するホームページの Link レスポンスヘッダーです。Link: </.well-known/mcp/server-card.json>; rel="mcp-server-card" を読み取ったエージェントは、追加の往復なしで次のステップを無料で手に入れます。robots ファイルは Robots.txt Validator で検証し、オリジンがいま何を送信しているかは HTTP Header Checker で確認してください。
コンテンツアクセシビリティ: リクエストに応じて Markdown を返す
ここでほとんどのサイトが失敗しますが、最も安価に修正できる箇所でもあります。acceptmarkdown.com の提案では、クライアントが Accept: text/markdown を送ったとき、サーバーは HTML ではなく Markdown として同じコンテンツを返すべきだとされています。チェッカーはここで4つのプローブを実行します。
1つ目は、サーバーがそのヘッダーを尊重し Content-Type: text/markdown; charset=utf-8 を返すことの確認です。2つ目は Vary: Accept の有無の確認です。このヘッダーを省くと、CDN は次に Markdown を要求したエージェントにキャッシュ済みの HTML 本文を返してしまい、そのキャッシュの背後にいるすべての AI クライアントへのレスポンスを汚染します。3つ目に、サポートされていない Accept タイプには、サイレントな HTML フォールバックではなく 406 Not Acceptable を返すべきです。4つ目に、サーバーは q 値を尊重すべきで、text/markdown;q=1.0, text/html;q=0.1 が実際に Markdown を返すようにします。
私たち自身の監査では、初回実行の典型的なスコアはここで4点中0点ですが、HTML をオンデマンドで Markdown に変換する CDN ワーカー1つで、午後のうちに4つすべてが修正されます。それ以降は、すべてのエージェントがナビゲーションの装飾と格闘する代わりに、クリーンでトークン化されたコンテンツのコピーを引き出します。この問いのコンテンツ構造の側面については、AI Readiness Checker がページの解析しやすさを採点します。
引用カプセル
Markdown コンテンツネゴシエーションは acceptmarkdown.com の提案に従います。クライアントが Accept: text/markdown を送ると、サーバーは Content-Type: text/markdown; charset=utf-8 と Vary: Accept を付けて Markdown を返します。Vary を省くと、CDN が Markdown を要求したエージェントにキャッシュ済みの HTML を返し、そのキャッシュの背後にいるすべての AI クライアントのレスポンスを破損させてしまいます。
AI ボットのアクセスとアイデンティティをどう管理すべきか
沈黙はポリシーではありません。AI エージェントを名指ししないデフォルトの robots.txt は、すべてのクローラーにあなたの意図を推測させることになり、その推測はあなたに不利に働きます。ボットアクセスのレイヤーは、明示的なルール、別個のコンテンツシグナルポリシー、そして公開された Web Bot Auth 鍵ディレクトリを評価します。これにより、本物のエージェントと、その名を騙るスクレイパーを見分けられるのです。
GPTBot は明示することの意義を物語っています。2024年5月と2025年5月を比較すると、AI とサーチクローラーの合計トラフィックに占める GPTBot の割合は2.2%から7.7%へと上昇し、生のリクエスト数では305%の増加で、9位から3位へと順位を上げました(Cloudflare、2025年)。1つのエージェントがこれほど急成長するとき、一律に「すべてブロック」というルールは現実のリーチを犠牲にします。
robots.txt でエージェントを名指しする
チェッカーは、いま重要なクローラーを対象としたルールをスキャンします。GPTBot、ChatGPT-User、OAI-SearchBot、ClaudeBot、Google-Extended、PerplexityBot、Meta-ExternalAgent、Applebot-Extended、Bytespider、CCBot、Amazonbot などです。名指しされたエージェントが3つ以上あれば合格となります。User-agent: GPTBot に続けて Allow: / と書くことは、ポリシーエンジンが拠り所にできる公開された約束であり、何も言わないこととは大きく異なります。バージョン間でのクローラーの挙動を確認したい場合は、姉妹ガイドの GPTBot vs ChatGPT-User vs ClaudeBot がどの名前が何をするかを解説しています。
Content Signals でトレーニングとリトリーバルを分ける
Cloudflare の Content Signals の提案は、robots.txt 内に3つのディレクティブ search、ai-input、ai-train を追加します。これにより、根拠のある回答を許可してブランドが AI の引用に表示され続けるようにしつつ、モデルのトレーニングは拒否できます。チェッカーは Content-Signal: ディレクティブが1つでもあれば合格とします。GPTBot を全面的にブロックするのは大ざっぱな一撃で、引用とトレーニングをまとめて切り捨ててしまいます。robots.txt で AI の可視性を妨げるもの の解説では、よくある過剰ブロックを取り上げています。
Web Bot Auth でエージェントを検証する
Web Bot Auth を使うと、エージェントは Ed25519 鍵ペアでリクエストに署名し、公開鍵を /.well-known/http-message-signature-directory で JWKS として公開できます。これは提案から実運用へと急速に移行しています。AWS WAF は2025年11月に Web Bot Auth サポートを発表し(AWS、2025年)、その基盤となる IETF の取り組みには Cloudflare、Anthropic、OpenAI が名を連ねています。チェッカーはそのディレクトリを調べ、JSON が返ることを確認します。これがなければ、正規のエージェントとなりすましを区別できません。検証されたエージェントには、より緩いレート制限とより広いアクセスが与えられます。
どのプロトコルがエージェントにサイトをツールとして使わせるのか
プロトコル検出はこのチェッカーの中核であり、25%という最も重いレイヤーです。あなたのサイトをドキュメントから呼び出し可能なツールへと変える /.well-known/ エンドポイントとページ内のアノテーションを調べます。その軸となるのが Model Context Protocol で、Anthropic が2024年11月25日にオープンソース化し(Anthropic、2024年)、OpenAI と Google が1年以内に採用しました。
MCP サーバーカード
/.well-known/mcp/server-card.json にある MCP サーバーカードは、サーバーの名前、機能、トランスポート、認証モデルを公示します。チェッカーはそのパスを調べ、見つからなければ /.well-known/mcp.json にフォールバックします。製品に何らかの API があるなら、サーバーカードはあなたのサイトを「スクレイプする対象」から「呼び出す対象」へと反転させる変更です。カードを見つけたエージェントは HTML の解析をやめ、関数の呼び出しを始めます。これはあなたにとって安価で、ユーザーにとって高速です。
ブラウザ内エージェントのための WebMCP
MCP はサーバー間の世界を前提としていますが、いまや多くのエージェント活動はブラウザのタブ内で起きており、WebMCP がそのギャップを埋めます。/.well-known/ の URL の代わりに、<form> 要素にツール属性で直接アノテーションを付けるか、<meta name="webmcp"> タグでツールを宣言し、すでにページにいるエージェントに呼び出し可能なアクションを公開します。この提案は2025年に Google と Microsoft の共同の取り組みとして登場し、W3C Community Group に受け入れられ、Chrome が早期プレビューを出荷しました。そのため正確なバージョン番号は流動的なものとして扱ってください。チェッカーはホームページからどちらのパターンも探します。実践的な教訓はこうです。コンバージョンがページ内で起きるなら、サーバーサイドの MCP だけではエージェントはあなたのフォームで立ち往生します。
API カタログと OAuth 検出
さらに2つの検出面がこのレイヤーを締めくくります。RFC 9727 は、公開するすべての API への application/linkset+json 形式のポインターとして /.well-known/api-catalog を定義します。多くのオリジンは、このパスを application/json で提供しているためにここで警告を受けますが、ヘッダー1つで修正できます。次に OAuth 検出です。/.well-known/oauth-authorization-server の RFC 8414 メタデータは、認証フローの開始方法をエージェントに伝えます。/.well-known/oauth-protected-resource の RFC 9728 メタデータは、401 を受け取った際にどの発行者とスコープを使うべきかを伝えます。OAuth 検出がなければ、どのエージェントもあなたのサイトでサインインを伴うアクションを自動化できません。
引用カプセル
Anthropic が2024年11月25日にオープンソース化した Model Context Protocol(Anthropic、2024年)は、/.well-known/mcp/server-card.json の MCP サーバーカードを通じて、エージェントが呼び出し可能なツールを検出できるようにします。およそ1年のうちに OpenAI と Google が採用し、MCP は Agent Protocol Readiness Checker が最初に調べる事実上の検出レイヤーになりました。
エージェントは実際にあなたへ支払えるのか
エージェントコマースは最も新しいレイヤーで、25%という最も重い重みで並んでいます。問いは率直です。エージェントがユーザーのためにあなたから購入したいとき、その取引はどのようなものになるのか。Adobe Analytics は、米国の小売サイトへの生成 AI ソース経由の訪問が2024年7月から2025年2月にかけて1,200%急増したと報告しました(Adobe、2025年)。リファラルはすでに届いています。チェックアウトを整えておく必要があるのです。
ここから先は賭け金がさらに大きくなります。Gartner は、2028年までに AI エージェントが15兆ドルを超える B2B 支出を仲介すると予測しています(Gartner、出典 Digital Commerce 360、2025年)。コマースのスコアで合格するのに、すべての標準をサポートする必要はありません。少なくとも1つで十分です。なぜなら「エージェントがあなたに支払える」は1つの機能であり、その所有権を巡って4つのプロトコルが競合しているからです。
x402: 最もコミットメントの低い道
x402 は HTTP ステータス 402「Payment Required」を復活させ、価格、通貨、決済エンドポイントを列挙した機械可読のオファーヘッダーを伴います。エージェントは 402 を受け取り、支払いに署名し、再送信してリソースを取得します。採用は本物です。Coinbase の x402 プロトコルは2026年初頭までに Base ネットワーク上で累計1億件の取引を突破しました(Crypto Briefing、2026年)。ただしオンチェーンの数値は中立的な監査人ではなくプロジェクト由来です。有料エンドポイントを1つ選び、条件を伴う 402 を返せば、それで稼働開始です。
ACP: 小売向けの完全なチェックアウト
Agentic Commerce Protocol はより充実した面です。Stripe と OpenAI は2025年9月29日に ChatGPT の Instant Checkout と並べて ACP を立ち上げ(Stripe Newsroom、2025年)、米国の Etsy 出品者と、Glossier、Vuori、Spanx、SKIMS を含む100万を超える Shopify マーチャントから始めました。ACP は /.well-known/agentic-commerce に置かれ、カタログ、価格、税、配送、返品を記述します。物品を販売し、ChatGPT に直接取引させたいなら、これが進むべきレーンです。
UCP と MPP: より軽量でより汎用的
初期段階の選択肢が2つ、このレイヤーを締めくくります。チェッカーはこれらを確立された標準ではなく新興のものとして扱います。UCP は OAuth に便乗します。ucp:scopes:checkout_session のようなコマーススコープを OAuth メタデータ内で宣言するので、すでにトークンを出荷しているなら半ばできています。/.well-known/machine-payments で公示される MPP は最も汎用的で、ステーブルコインから銀行送金、トークン単位の従量課金まで、受け入れる機械間レールを記述します。どちらも MCP、ACP、x402 が持つような文書化された一次情報の裏付けがないため、自前の仕様から定義し、それらがどう収束していくかを見守ってください。
スコアの読み方とギャップの直し方
チェッカーは5つのレイヤーを重み付けして A から F のグレードにまとめます。85を超えるスコアは A、70から84は B で、低いグレードは意図的に急激に下がります。D レンジのサイトはツールを公示せず、Markdown を返さず、エージェントの支払いも受け付けないため、エージェント主導のトラフィックにとってはパークドメインのように見えるのです。私たちの監査では、ほとんどのサイトが10から30の間でスタートします。
| レイヤー | 重み |
|---|---|
| 発見可能性 | 15% |
| コンテンツアクセシビリティ | 20% |
| ボットアクセス制御 | 15% |
| プロトコル検出 | 25% |
| エージェントコマース | 25% |
その低い出発点は想定内であり、十分に対処できます。ツールはレバレッジの最も高い6つの修正を浮かび上がらせ、そのうち3つを片付けるだけで、通常はサイトを1日のうちに F から C へと引き上げます。
直す順序の実践例
各修正が次のロック解除につながるよう、依存関係の順にレイヤーを進めましょう。
- GPTBot、ClaudeBot、Google-Extended、PerplexityBot に対する明示的な
User-agent:ルールとSitemap:行を備えた有効な robots.txt を公開します。Robots.txt Validator で検証してください。 - CDN エッジで Markdown コンテンツネゴシエーションを追加します。
Accept: text/markdownを尊重し、Vary: Acceptを設定し、サポートされていないタイプには 406 を返します。 - エージェントに最も引用してほしいページを指すルートの llms.txt を公開します。LLMs.txt Generator + Validator で生成して検証し、llms.txt は必要か についての私たちの見解も参照してください。
- エージェントがツールを検出できるよう、
/.well-known/mcp/server-card.jsonに最小限の MCP サーバーカードを公開します。 - robots.txt に Content Signals ディレクティブを1つ追加し、トレーニングとリトリーバルの実際のポリシーを公開します。
- 検証済みのエージェントがリクエストに署名できるよう、Web Bot Auth の JWKS を公開します。
私たちがチェッカーにかけてきたサイト全体で見ると、この一連の作業は通常の CDN と認証スタックでおよそ2エンジニア日分であり、確実にオリジンを F から B へと引き上げます。robots ルールが実際にクローラーを通しているかを確認するには、AI クローラーがサイトにアクセスできるか確認する方法 のガイドと組み合わせてください。
FAQ
エージェント対応は SEO や AEO と違うのか
はい、違います。SEO は検索順位を調整し、Answer Engine Optimization はチャットアシスタントによる引用のされ方を調整します。エージェント対応が調整するのは、ソフトウェアがそもそもあなたのオリジンと取引できるかどうか、つまりツールを検出し、コンテンツをネゴシエートし、サインインし、支払えるかどうかです。あるページが上位に表示されても、自律的な予約エージェントにとっては行き止まりということがあり得ます。
最も早くリターンが出る修正はどれか
Markdown コンテンツネゴシエーションです。ほとんどのサイトは4点中0点ですが、Accept: text/markdown を尊重し、Vary: Accept を設定し、サポートされていないタイプに 406 を返す CDN ワーカー1つで、午後のうちに4つすべてのプローブが解決します。コンテンツアクセシビリティはグレードの20%を占めるため、時間あたりの得点効率が高いのです。
すべてのコマースプロトコルをサポートする必要があるか
いいえ。エージェントコマースのレイヤーは標準が1つあれば合格します。「エージェントがあなたに支払える」は1つの機能であり、その所有権を巡って4つのプロトコルが競合しているからです。自分に合うものを選びましょう。コミットメントの低い有料エンドポイントには x402、小売の完全なチェックアウトには ACP、すでに OAuth トークンを出荷しているなら UCP です。
エージェントトラフィックは実際どれくらい速く伸びているのか
急速です。AI ボットは2025年に Cloudflare のネットワーク上で HTML リクエストの4.2%に達し(Cloudflare Radar、2025年)、GPTBot のクローラーシェアは生のリクエスト数で前年比305%上昇し(Cloudflare、2025年)、生成 AI ソース経由の小売訪問は8か月で1,200%急増しました(Adobe、2025年)。
これらのチェックは来年も同じままか
いいえ、そしてそれで構いません。MCP は機能ネゴシエーションを正式化し、WebMCP のバージョンの詳細はまだ流動的で、コマースプロトコルは収束していくでしょう。私たちは標準が定着すればプローブを追加し、デフォルトになれば廃止します。問題の形は変わりません。サイトに何ができるかを、最初の数回のリクエストで明確に公開することです。
次に何をすべきか
ホームページに対して Agent Protocol Readiness Checker を実行し、上位3つの推奨事項を直してから、もう一度実行して、エージェントがあなたのオリジンをいかに違う扱い方をするかを見てください。プローブは無料でブラウザベースで動作し、すべての判定の裏にある生のサーバー証跡を返します。
そこから、2つの姉妹ガイドがさらに深く掘り下げます。robots ルールが思った通りに機能しているかを確認するには AI クローラーがサイトにアクセスできるか確認する方法 を、エージェントがたどり着いたコンテンツを引用に値するものにするには Answer Engine Optimization の完全ガイド をお読みください。