Gotowość na agentów: jak przygotować witrynę na sieć agentową
Agenci AI już dawno przestali tylko czytać strony. Rezerwują loty, zamawiają części, finalizują zamówienia i logują się do API w imieniu swoich użytkowników. Witryny, które udostępniają właściwe sygnały, są używane. Witryny, które tego nie robią, są pomijane. Nowe narzędzie Agent Protocol Readiness Checker skanuje Twój adres URL pod kątem dokładnie tych sygnałów, których agenci teraz szukają.
- Agenci AI
- MCP
- Handel agentowy
- Techniczne SEO
Dlaczego sieć agentowa potrzebuje własnego audytu
Nowa klasa odwiedzających dociera teraz do Twojego serwera, zanim zrobi to jakikolwiek człowiek: to oprogramowanie, które działa. Cloudflare zmierzył, że w 2025 roku ruch botów AI stanowił 4,2% wszystkich żądań HTML w jego sieci (Cloudflare Radar 2025 Year in Review, 2025). Ten udział kupuje, rezerwuje i loguje się. Narzędzie Agent Protocol Readiness Checker sprawdza, czy Twoja witryna potrafi go obsłużyć.
Najważniejsze wnioski
- Boty AI generują już około 4,2% żądań HTML w sieci Cloudflare (Cloudflare Radar, 2025), a ten udział rośnie.
- Agenci sprawdzają ścieżki
/.well-known/, negocjację treści i klucze uwierzytelniania botów, zanim w ogóle przeanalizują Twój kod HTML.- Narzędzie ocenia pięć warstw: wykrywalność, dostęp do treści, tożsamość, możliwości i handel.
- Większość witryn przy pierwszym uruchomieniu uzyskuje wynik między 10 a 30. Trzy celowane poprawki zwykle przenoszą je do poziomu zaliczającego.
- Zacznij od luk o najwyższej wadze: negocjacja Markdown i wykrywanie protokołów łącznie odpowiadają za 45% oceny.
Pomyśl o kolejności, w jakiej działa nowoczesny agent. Nie otwiera Twojej strony głównej i nie zaczyna czytać od góry do dołu jak człowiek. On sonduje. Najpierw zadaje Twojemu serwerowi kilka ostrych pytań: czy serwujesz czysty Markdown, czy publikujesz manifest narzędzi, czy przyjmujesz podpisane żądania, czy potrafisz przyjąć płatność? Dopiero gdy te sondy zawiodą, wraca do zeskrobywania surowego kodu HTML, co jest powolne i stratne.
To właśnie zachowanie sondujące sprawia, że gotowość na agentów jest osobną dyscypliną. SEO dostraja sposób, w jaki rankuje Cię Google. Optymalizacja silnika odpowiedzi dostraja sposób, w jaki cytują Cię asystenci czatu. Gotowość na agentów dostraja coś innego: czy oprogramowanie w ogóle może z Tobą zawrzeć transakcję. To narzędzie jest audytem protokołów, nie audytem treści. Pokazuje, warstwa po warstwie, w którym miejscu agent rezygnuje.
Co mierzy Agent Protocol Readiness Checker?
Narzędzie uruchamia ponad 20 sond wobec adresu URL i grupuje je w pięć ocenianych warstw, ważonych według wpływu. Wykrywanie protokołów i handel agentowy odpowiadają po 25% oceny, dostępność treści po 20%, a wykrywalność i dostęp botów po 15% każde. Każda sonda zwraca wynik zaliczony, ostrzeżenie lub niezaliczony, wraz z dołączonym surowym dowodem z serwera.

Rysunek 1: Pięć warstw, które ocenia agent, oraz waga każdej z nich w ocenie końcowej.
Sens warstwowania tkwi w kolejności. Agent, który nie potrafi znaleźć Twojego pliku robots.txt, nigdy nie dotrze do pytania, czy serwujesz Markdown. Agent, który nie potrafi czysto odczytać Twoich treści, rzadko zadaje sobie trud sprawdzenia, czy publikujesz narzędzia. Niepowodzenia kaskadują w dół, więc niższe warstwy blokują wszystko powyżej.
Kapsuła cytowania
Agent Protocol Readiness Checker ocenia pięć ważonych warstw w ponad 20 sondach: wykrywalność i dostęp botów po 15% każde, dostępność treści po 20%, a wykrywanie protokołów oraz handel agentowy po 25% każde. Każda sonda zwraca wynik zaliczony, ostrzeżenie lub niezaliczony, z surowym dowodem z serwera. Boty AI generują już 4,2% żądań HTML (Cloudflare Radar, 2025).
Zbudowaliśmy je, ponieważ istniejące narzędzia odpowiadają na niewłaściwe pytanie. Większość audytów pyta „czy Google zrankuje tę stronę”. Potrzebowaliśmy takiego, które pyta „czy autonomiczny agent może skorzystać z tego serwera bez udziału człowieka”. To nie są te same witryny. Strona może rankować znakomicie i wciąż być ślepą uliczką dla agenta rezerwującego.
Jak agenci wykrywają i odczytują Twoją witrynę?
Wykrywalność i dostęp do treści to dwie pierwsze warstwy, które decydują o tym, czy agent w ogóle zacznie. Agenci najpierw rozwiązują plik robots.txt, potem odczytują nagłówki odpowiedzi Link w poszukiwaniu wskazówek, a następnie negocjują typ treści. Większość serwerów uzyskuje zero punktów za negocjację Markdown, choć to pojedyncza poprawka o najlepszym stosunku zwrotu do wysiłku w przypadku ruchu pośredniczonego przez AI.
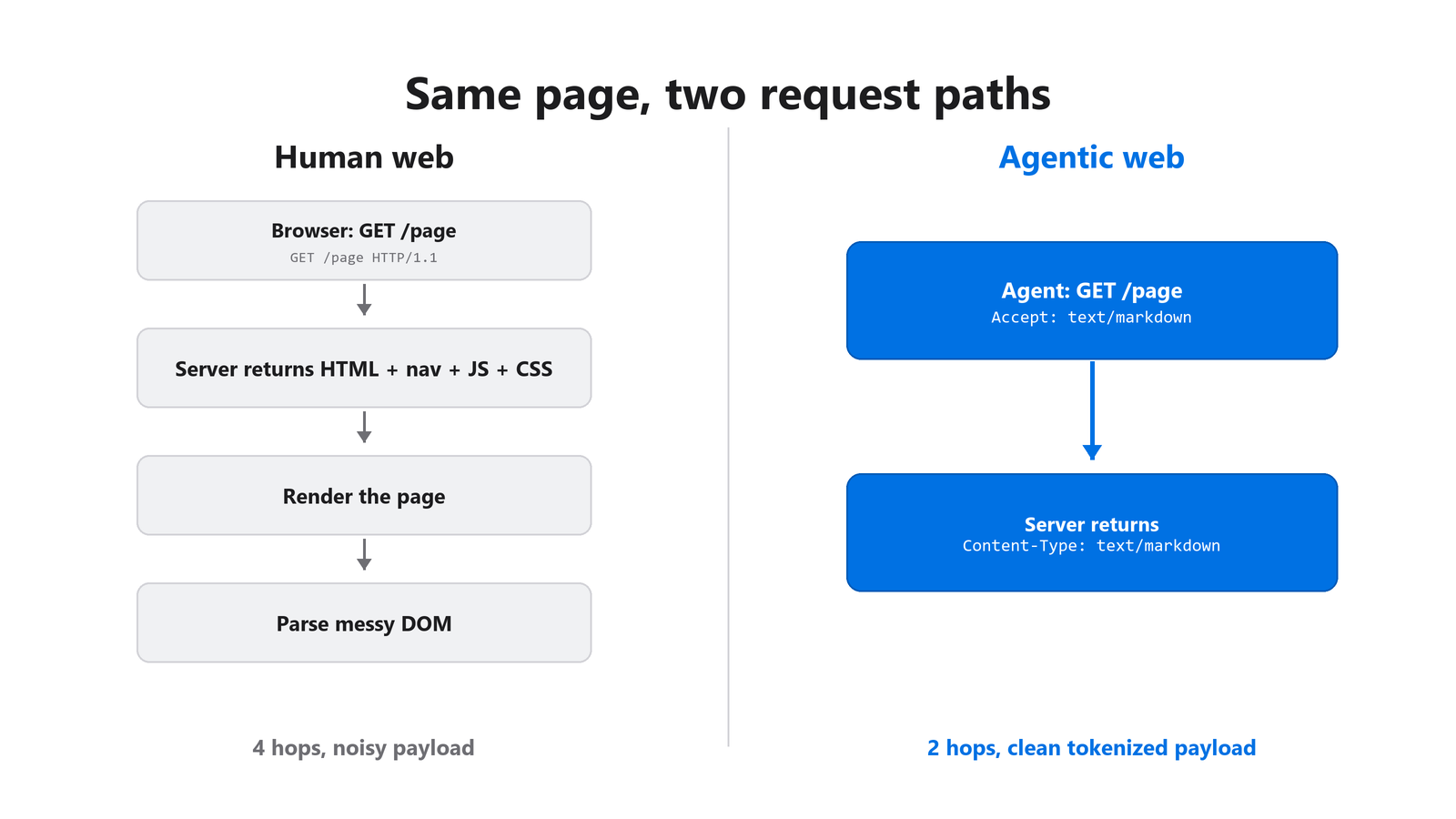
Rysunek 2: Sieć ludzka zwraca wyrenderowany HTML. Sieć agentowa zwraca wynegocjowany Markdown w mniejszej liczbie kroków.
Wykrywalność: pliki, które agenci rozwiązują jako pierwsze
Trzy zwykłe pliki przygotowują grunt. Poprawny robots.txt zgodny z RFC 9309, mapa witryny, na którą plik robots wskazuje wierszem Sitemap:, oraz nagłówki odpowiedzi Link na Twojej stronie głównej, które podpowiadają zasoby w /.well-known/. Agent, który odczyta Link: </.well-known/mcp/server-card.json>; rel="mcp-server-card", dostaje swój kolejny krok za darmo, bez dodatkowego obiegu. Sprawdź plik robots naszym narzędziem Robots.txt Validator, a to, co Twój serwer wysyła dzisiaj, zbadaj narzędziem HTTP Header Checker.
Dostępność treści: serwuj Markdown na żądanie
To tutaj zawodzi większość witryn, i tutaj naprawa jest najtańsza. Propozycja acceptmarkdown.com mówi, że gdy klient wysyła Accept: text/markdown, Twój serwer powinien zwrócić tę samą treść jako Markdown, a nie HTML. Narzędzie uruchamia tu cztery sondy.
Po pierwsze, potwierdza, że serwer honoruje nagłówek i zwraca Content-Type: text/markdown; charset=utf-8. Po drugie, sprawdza nagłówek Vary: Accept. Pomiń go, a CDN może podać zbuforowaną treść HTML kolejnemu agentowi, który poprosił o Markdown, zatruwając odpowiedź dla każdego klienta AI za tym buforem. Po trzecie, nieobsługiwany typ Accept powinien zwrócić 406 Not Acceptable, a nie cichą rezerwę w postaci HTML. Po czwarte, serwer powinien respektować wartości q, tak aby text/markdown;q=1.0, text/html;q=0.1 faktycznie zwracało Markdown.
W naszych własnych audytach typowy pierwszy przebieg uzyskuje tu zero z czterech, a pojedynczy worker CDN, który na żądanie przekształca HTML w Markdown, naprawia wszystkie cztery w jedno popołudnie. Potem każdy agent pobiera czystą, stokenizowaną kopię Twojej treści, zamiast mocować się z nawigacyjnym balastem. Dla strony tego zagadnienia dotyczącej struktury treści nasze narzędzie AI Readiness Checker ocenia, jak dobrze Twoje strony dają się parsować.
Kapsuła cytowania
Negocjacja treści Markdown jest zgodna z propozycją acceptmarkdown.com: gdy klient wysyła Accept: text/markdown, serwer zwraca Markdown z nagłówkami Content-Type: text/markdown; charset=utf-8 oraz Vary: Accept. Pominięcie Vary pozwala CDN podać zbuforowany HTML agentom proszącym o Markdown, psując odpowiedzi dla każdego klienta AI za tym buforem.
Jak zarządzać dostępem i tożsamością botów AI?
Milczenie nie jest polityką. Domyślny robots.txt, który nie wymienia żadnego agenta AI, pozostawia każdemu crawlerowi zgadywanie Twoich intencji, a domysły działają na Twoją niekorzyść. Warstwa dostępu botów nagradza jawne reguły, osobną politykę sygnałów treści oraz opublikowany katalog kluczy Web Bot Auth, dzięki któremu odróżnisz prawdziwego agenta od skrobaka podszywającego się pod jego nazwę.
GPTBot przemawia za jawnością. W porównaniu maja 2024 do maja 2025 udział GPTBot w łącznym ruchu crawlerów AI i wyszukiwania wzrósł z 2,2% do 7,7%, co oznacza wzrost surowych żądań o 305% i przesunięcie z dziewiątego na trzecie miejsce (Cloudflare, 2025). Gdy jeden agent rośnie tak szybko, hurtowa reguła „blokuj wszystko” kosztuje Cię realny zasięg.
Wymień agentów w robots.txt
Narzędzie skanuje reguły wymierzone w crawlery, które liczą się dzisiaj: GPTBot, ChatGPT-User, OAI-SearchBot, ClaudeBot, Google-Extended, PerplexityBot, Meta-ExternalAgent, Applebot-Extended, Bytespider, CCBot, Amazonbot i inne. Trzech lub więcej wymienionych agentów daje wynik zaliczony. Zapisanie User-agent: GPTBot, a potem Allow: /, to publiczne zobowiązanie, na którym może oprzeć się silnik polityki, co jest czymś zupełnie innym niż milczenie. Jeśli chcesz potwierdzić zachowanie crawlerów w różnych wersjach, nasz bratni przewodnik GPTBot vs ChatGPT-User vs ClaudeBot rozkłada na czynniki pierwsze, która nazwa za co odpowiada.
Oddziel trenowanie od pobierania dzięki Content Signals
Propozycja Content Signals od Cloudflare dodaje do robots.txt trzy dyrektywy: search, ai-input i ai-train. Pozwalają one dopuścić ugruntowane odpowiedzi, dzięki czemu Twoja marka wciąż pojawia się w cytowaniach AI, jednocześnie odmawiając trenowania modeli. Narzędzie zalicza warstwę przy dowolnej pojedynczej dyrektywie Content-Signal:. Całkowite zablokowanie GPTBot to tępe uderzenie, które usuwa naraz cytowania i trenowanie. Nasze omówienie tego, co blokuje widoczność AI w robots.txt, opisuje najczęstsze nadmierne blokady.
Weryfikuj agentów dzięki Web Bot Auth
Web Bot Auth pozwala agentom podpisywać żądania parą kluczy Ed25519, publikując klucz publiczny jako JWKS pod adresem /.well-known/http-message-signature-directory. Szybko przechodzi od propozycji do produkcji: AWS WAF ogłosił obsługę Web Bot Auth w listopadzie 2025 (AWS, 2025), a za leżącymi u podstaw pracami IETF stoją Cloudflare, Anthropic i OpenAI. Narzędzie sonduje ten katalog i potwierdza, że zwraca on JSON. Bez niego nie udowodnisz, że legalny agent różni się od podszywacza, a zweryfikowani agenci otrzymują niższe limity szybkości i szerszy dostęp.
Jakie protokoły pozwalają agentom używać Twojej witryny jak narzędzia?
Wykrywanie protokołów to serce narzędzia i jego najcięższa warstwa z wagą 25%. Przygląda się punktom końcowym /.well-known/ oraz adnotacjom na stronie, które zmieniają Twoją witrynę z dokumentu w wywoływalne narzędzie. Filarem jest tu Model Context Protocol, który Anthropic udostępnił jako open source 25 listopada 2024 (Anthropic, 2024) i który OpenAI oraz Google przyjęły w ciągu roku.
MCP Server Card
MCP Server Card pod adresem /.well-known/mcp/server-card.json reklamuje nazwę serwera, jego możliwości, transport i model uwierzytelniania. Narzędzie sonduje tę ścieżkę i w razie braku wraca do /.well-known/mcp.json. Jeśli Twój produkt ma jakiekolwiek API, Server Card to zmiana, która przełącza Twoją witrynę z „zeskrob ją” na „wywołaj ją”. Agent, który znajdzie kartę, przestaje parsować HTML i zaczyna wywoływać funkcje, co jest tańsze dla Ciebie i szybsze dla użytkownika.
WebMCP dla agentów w przeglądarce
MCP zakłada świat serwer-serwer, ale spora część aktywności agentów dzieje się teraz wewnątrz karty przeglądarki, i tę lukę wypełnia WebMCP. Zamiast adresu /.well-known/, opisujesz elementy <form> bezpośrednio atrybutami narzędzi lub deklarujesz narzędzia znacznikiem <meta name="webmcp">, udostępniając wywoływalne akcje agentowi, który już jest na stronie. Propozycja pojawiła się jako wspólne przedsięwzięcie Google i Microsoftu w 2025 roku i została przyjęta przez grupę społecznościową W3C, a Chrome wypuścił wczesną wersję podglądową, więc traktuj konkretne numery wersji jako ruchomy cel. Narzędzie skanuje Twoją stronę główną w poszukiwaniu dowolnego z tych wzorców. Praktyczny wniosek: jeśli Twoje konwersje dzieją się na stronie, samo MCP po stronie serwera zostawia agentów uwięzionych przy Twoich formularzach.
Katalog API i wykrywanie OAuth
Warstwę dopełniają dwie kolejne powierzchnie wykrywania. RFC 9727 definiuje /.well-known/api-catalog jako wskaźnik application/linkset+json do każdego udostępnianego przez Ciebie API. Wiele serwerów otrzymuje tu ostrzeżenie, bo obsługuje tę ścieżkę z application/json zamiast właściwego typu, co jest poprawką jednego nagłówka. Dalej wykrywanie OAuth: metadane RFC 8414 pod adresem /.well-known/oauth-authorization-server mówią agentowi, jak rozpocząć przepływ uwierzytelniania, a metadane RFC 9728 pod adresem /.well-known/oauth-protected-resource mówią mu, przy odpowiedzi 401, którego wystawcy i jakich zakresów użyć. Bez wykrywania OAuth żaden agent nie zautomatyzuje na Twojej witrynie działania wymagającego zalogowania.
Kapsuła cytowania
Model Context Protocol, udostępniony jako open source przez Anthropic 25 listopada 2024 (Anthropic, 2024), pozwala agentom wykrywać wywoływalne narzędzia poprzez MCP Server Card pod adresem /.well-known/mcp/server-card.json. W ciągu mniej więcej roku OpenAI i Google przyjęły go, czyniąc z MCP faktyczną warstwę wykrywania, którą Agent Protocol Readiness Checker sonduje jako pierwszą.
Czy agent może Ci faktycznie zapłacić?
Handel agentowy to najnowsza warstwa, która remisuje jako najcięższa z wagą 25%. Pytanie jest bezpośrednie: gdy agent chce u Ciebie kupić coś dla swojego użytkownika, jak wygląda taka transakcja? Adobe Analytics ustaliło, że wizyty na amerykańskich witrynach detalicznych ze źródeł generatywnej AI wzrosły o 1200% między lipcem 2024 a lutym 2025 (Adobe, 2025). Odesłania już przychodzą. Kasa musi być gotowa.
Stawka rośnie od tego miejsca. Gartner prognozuje, że agenci AI będą pośredniczyć w ponad 15 bilionach dolarów wydatków B2B do 2028 roku (Gartner, za Digital Commerce 360, 2025). Wynik zaliczający w handlu nie wymaga obsługi każdego standardu. Wymaga co najmniej jednego, ponieważ „agent może Ci zapłacić” to jedna funkcja, o którą rywalizują cztery protokoły.
x402: ścieżka o najmniejszym zobowiązaniu
x402 wskrzesza status HTTP 402, „Payment Required”, dodając nagłówek oferty czytelny maszynowo, który podaje cenę, walutę i punkt końcowy rozliczenia. Agent otrzymuje 402, podpisuje płatność, ponawia żądanie i dostaje zasób. Adopcja jest realna: protokół x402 firmy Coinbase przekroczył 100 milionów skumulowanych transakcji w sieci Base do początku 2026 (Crypto Briefing, 2026), przy czym dane on-chain pochodzą od samego projektu, a nie od neutralnego audytora. Wybierasz jeden płatny punkt końcowy, zwracasz 402 z warunkami i działasz.
ACP: pełna kasa dla handlu detalicznego
Agentic Commerce Protocol to pełniejsza powierzchnia. Stripe i OpenAI uruchomiły ACP wraz z Instant Checkout w ChatGPT 29 września 2025 (Stripe Newsroom, 2025), zaczynając od amerykańskich sprzedawców Etsy i ponad miliona sprzedawców Shopify, w tym Glossier, Vuori, Spanx i SKIMS. ACP działa pod adresem /.well-known/agentic-commerce i opisuje katalog, ceny, podatki, wysyłkę oraz zwroty. Jeśli sprzedajesz towary i chcesz, by ChatGPT przeprowadzał transakcje bezpośrednio, to jest Twój pas ruchu.
UCP i MPP: lżejsze i bardziej ogólne
Warstwę dopełniają dwie opcje na wcześniejszym etapie, a narzędzie traktuje je jako powstające, a nie ustalone standardy. UCP korzysta z OAuth: deklarujesz zakresy handlowe, takie jak ucp:scopes:checkout_session, wewnątrz swoich metadanych OAuth, więc jeśli już wydajesz tokeny, jesteś w połowie drogi. MPP, reklamowany pod adresem /.well-known/machine-payments, jest najbardziej ogólny i opisuje, jakie szyny maszyna-maszyna akceptujesz, od stablecoinów przez przelewy bankowe po rozliczanie za token. Żaden z nich nie ma udokumentowanego oparcia w źródłach pierwotnych, jakie mają MCP, ACP i x402, więc zdefiniuj je na podstawie własnej specyfikacji i obserwuj, jak się konsolidują.
Jak odczytać wynik i naprawić luki?
Narzędzie składa pięć warstw w ważoną ocenę od A do F. Wyniki powyżej 85 dają A, od 70 do 84 dają B, a niższe oceny celowo spadają gwałtownie: witryna w przedziale D nie reklamuje narzędzi, nie serwuje Markdown ani nie przyjmuje płatności agentów, więc dla ruchu napędzanego przez agentów odczytuje się jak zaparkowana domena. W naszych audytach większość witryn zaczyna między 10 a 30.
| Warstwa | Waga |
|---|---|
| Wykrywalność | 15% |
| Dostępność treści | 20% |
| Kontrola dostępu botów | 15% |
| Wykrywanie protokołów | 25% |
| Handel agentowy | 25% |
Tak niski punkt startowy jest oczekiwany i da się z nim pracować. Narzędzie pokazuje sześć poprawek o największej dźwigni, a usunięcie trzech z nich zwykle przenosi witrynę z F do C w ciągu jednego dnia.
Praktyczna kolejność naprawiania
Pracuj nad warstwami w kolejności zależności, aby każda poprawka odblokowywała kolejną.
- Opublikuj poprawny robots.txt z jawnymi regułami
User-agent:dla GPTBot, ClaudeBot, Google-Extended i PerplexityBot oraz z wierszemSitemap:. Sprawdź go narzędziem Robots.txt Validator. - Dodaj negocjację treści Markdown na brzegu CDN: honoruj
Accept: text/markdown, ustawVary: Accept, zwracaj 406 dla nieobsługiwanych typów. - Opublikuj plik llms.txt w katalogu głównym, wskazując strony, które najbardziej chcesz, by agenci cytowali. Wygeneruj go i sprawdź narzędziem LLMs.txt Generator + Validator, a nasze stanowisko poznasz w tekście o tym, czy potrzebujesz llms.txt.
- Udostępnij minimalny MCP Server Card pod adresem
/.well-known/mcp/server-card.json, aby agenci mogli wykryć Twoje narzędzia. - Dodaj do robots.txt jedną dyrektywę Content Signals, aby opublikować prawdziwą politykę trenowanie kontra pobieranie.
- Opublikuj Web Bot Auth JWKS, aby zweryfikowani agenci mogli podpisywać żądania.
We wszystkich witrynach, które przepuściliśmy przez narzędzie, ta sekwencja to z grubsza dwa dni pracy inżyniera na zwykłym stosie CDN i uwierzytelniania, i niezawodnie przenosi serwer z F do B. Aby potwierdzić, że Twoje reguły robots faktycznie przepuszczają crawlery, połącz to z naszym przewodnikiem o tym, jak sprawdzić, czy crawlery AI mają dostęp do Twojej witryny.
FAQ
Czy gotowość na agentów różni się od SEO i AEO?
Tak. SEO dostraja ranking w wyszukiwaniu, a optymalizacja silnika odpowiedzi dostraja sposób, w jaki cytują Cię asystenci czatu. Gotowość na agentów dostraja to, czy oprogramowanie w ogóle może zawrzeć transakcję z Twoim serwerem: wykryć narzędzia, wynegocjować treść, zalogować się i zapłacić. Strona może dobrze rankować i wciąż być ślepą uliczką dla autonomicznego agenta rezerwującego.
Która poprawka daje najszybszy zwrot?
Negocjacja treści Markdown. Większość witryn uzyskuje tu zero z czterech, a pojedynczy worker CDN, który honoruje Accept: text/markdown, ustawia Vary: Accept i zwraca 406 dla nieobsługiwanych typów, naprawia wszystkie cztery sondy w jedno popołudnie. Dostępność treści odpowiada za 20% oceny, więc zwrot punktów na godzinę jest wysoki.
Czy muszę obsługiwać każdy protokół handlowy?
Nie. Warstwa handlu agentowego zalicza się przy dowolnym pojedynczym standardzie, ponieważ „agent może Ci zapłacić” to jedna funkcja, o którą rywalizują cztery protokoły. Wybierz ten, który pasuje: x402 dla płatnych punktów końcowych o niskim zobowiązaniu, ACP dla pełnej kasy detalicznej, UCP, jeśli już wydajesz tokeny OAuth.
Jak szybko faktycznie rośnie ruch agentów?
Szybko. Boty AI osiągnęły 4,2% żądań HTML w sieci Cloudflare w 2025 (Cloudflare Radar, 2025), udział crawlera GPTBot wzrósł o 305% w surowych żądaniach rok do roku (Cloudflare, 2025), a wizyty detaliczne ze źródeł generatywnej AI wzrosły o 1200% w osiem miesięcy (Adobe, 2025).
Czy te kontrole pozostaną takie same za rok?
Nie, i to jest w porządku. MCP sformalizuje negocjację możliwości, szczegóły wersji WebMCP wciąż się zmieniają, a protokoły handlowe się skonsolidują. Dodajemy sondy w miarę pojawiania się standardów i wycofujemy je, gdy stają się domyślne. Kształt problemu pozostaje: pokaż jasno, w pierwszych kilku żądaniach, co Twoja witryna potrafi.
Co zrobić dalej
Uruchom Agent Protocol Readiness Checker na swojej stronie głównej, napraw trzy najważniejsze rekomendacje, a potem uruchom je ponownie i zobacz, jak inaczej agenci traktują Twój serwer. Sondy są darmowe, działają w przeglądarce i zwracają surowy dowód z serwera stojący za każdym werdyktem.
Dalej w głąb prowadzą dwa bratnie przewodniki. Przeczytaj, jak sprawdzić, czy crawlery AI mają dostęp do Twojej witryny, aby potwierdzić, że Twoje reguły robots robią to, co myślisz, oraz kompletny przewodnik po optymalizacji silnika odpowiedzi, aby treść, do której docierają ci agenci, była warta cytowania.