アンサーエンジン最適化 (AEO) と GEO の完全ガイド
検索はもうリンクの一覧ではありません。AI 検索エンジンは直接的な回答と統合された概要を生成し、トラフィックは引用するに足る信頼を得たページへと流れます。アンサーエンジン最適化と生成エンジン最適化を前提にコンテンツを設計しなければ、新しい検索レイヤーで可視性を失います。
- AI検索
- AEO
- テクニカルSEO
アンサーエンジンとは何か、なぜ SEO を変えるのか
アンサーエンジンは、ユーザーの代わりにページを読み込み、統合した回答を書き上げます。そのため、かつて獲得していたクリックが、いまや回答ボックスの中で完結してしまいます。この変化は数値で確認できます。Google の AI による要約が表示された場合、ユーザーが従来型の検索結果をクリックしたのは訪問全体のわずか 8% で、要約がない場合の 15% を下回りました(Pew Research Center、2025年)。
20年間、取引はシンプルでした。質問を入力すれば10本のリンクが返ってきて、あとは自分で読む。エンジンは文書を取得し、回答を組み立てるのはユーザー自身でした。その作業が移動したのです。
いまでは Google の AI Overviews、Perplexity、ChatGPT Search が複数のページを読み込み、矛盾を解消し、回答そのものを書き上げます。あなたのサイトは末尾の引用として扱われるか、まったく取り上げられないかのどちらかです。その規模は本物で、ChatGPT は2025年後半に週間アクティブユーザー8億人を突破しました(Fortune、2025年)。
本ガイドは、これ以降の内容すべてをつなぐハブです。アンサーエンジンの仕組み、ページが抽出されやすくなる条件、引用が選ばれる過程、その土台にある検索パイプライン、そして取り組みが成果につながっているかを測る方法を扱います。まずは AI Readiness Checker でサイトを診断し、現在地をスコアで把握することから始めましょう。
重要なポイント
- AEO は抽出されやすさ(モデルがページからクリーンな事実を取り出せるか)に関わり、GEO は選定(引用するに足る信頼があるか)に関わります。両方が必要です。
- AI による要約が表示されると、従来型の検索結果のクリック率は要約なしの 15% に対して 8% まで低下します(Pew Research Center、2025年)。
- 引用、引用文、統計を加えることで、生成された回答における情報源の可視性を最大 40% 高められます(Aggarwal et al., KDD 2024)。
- ページ単位ではなくチャンク単位で書きましょう。各段落が検索の単位になるため、単独で成立している必要があります。
- 引用シェアは月ごとに大きく変動するため、どの数値も基準ではなくスナップショットとして扱ってください。
AEO と GEO はどう違うのか
AEO と GEO は同じパイプラインの両輪であり、同義語ではありません。AEO は、事実を一度の読み込みで抽出可能にする機械的な作業です。GEO は、モデルが引用するに足ると信頼する情報源になるための評判づくりの作業です。完璧に抽出可能なページでも見送られることはあるため、この順序で両方が必要になります。
「読む、それから選ぶ」と考えてください。リトリーバーがページをクリーンに読み込めて初めて、モデルは競合ではなくあなたを選べるのです。
アンサーエンジン最適化: 抽出されやすさ
アンサーエンジン最適化が問うのは一つだけです。モデルがあなたのページを読み込み、クリーンで引用しやすい事実を取り出せるか。従来の SEO は長い導入や前置きを評価しましたが、AEO はそれを減点します。リトリーバーはページを数百トークンのチャンクに分割し、各チャンクを単独で評価するからです。「本題に入る前に」で始まるチャンクは、答えで始まるチャンクに負けます。
これは午後の数時間で直せる問題です。ページを監査し、導入を書き直し、見出しを再構成し、もう一度測る。機械的な作業で、フィードバックも速い。
生成エンジン最適化: 選定
生成エンジン最適化が問うのは、より難しい問いです。リトリーバーが十数本の候補ページを取得したあと、モデルはどのページの事実を信頼するのか。GEO は、見送られる側ではなく、モデルが手を伸ばす情報源になるための作業です。この分野を命名した最初の学術研究では、GEO の手法(引用、引用文、統計の追加)が生成された応答における情報源の可視性を最大 40% 高められることが示されました(Aggarwal et al., KDD 2024)。
選定で評価を得るのは時間がかかります。AEO が完璧でも、生まれたばかりのサイトは、モデルの引用候補に入るための信頼シグナルをこれから築かなければなりません。
引用キャプセル: アンサーエンジン最適化は、モデルが一度の読み込みでページから引用可能な事実を抽出できるかを左右し、生成エンジン最適化は、モデルが引用するに足ると信頼するかを左右します。どちらも重要で、GEO の学術研究はこれらの手法が情報源の可視性を最大 40% 引き上げうると示しました(Aggarwal et al., KDD 2024)。
アンサーエンジンの検索パイプラインはどう動くのか
アンサーエンジンは、クロール、インデックス、検索、統合、引用という5段階のパイプラインを動かします。各段階が前の段階の結果を絞り込みます。クロールに失敗したページはインデックスされず、インデックスされても検索されないページは決して引用されません。自分がどこで脱落するかを理解すれば、何を最初に直すべきかが正確に分かります。
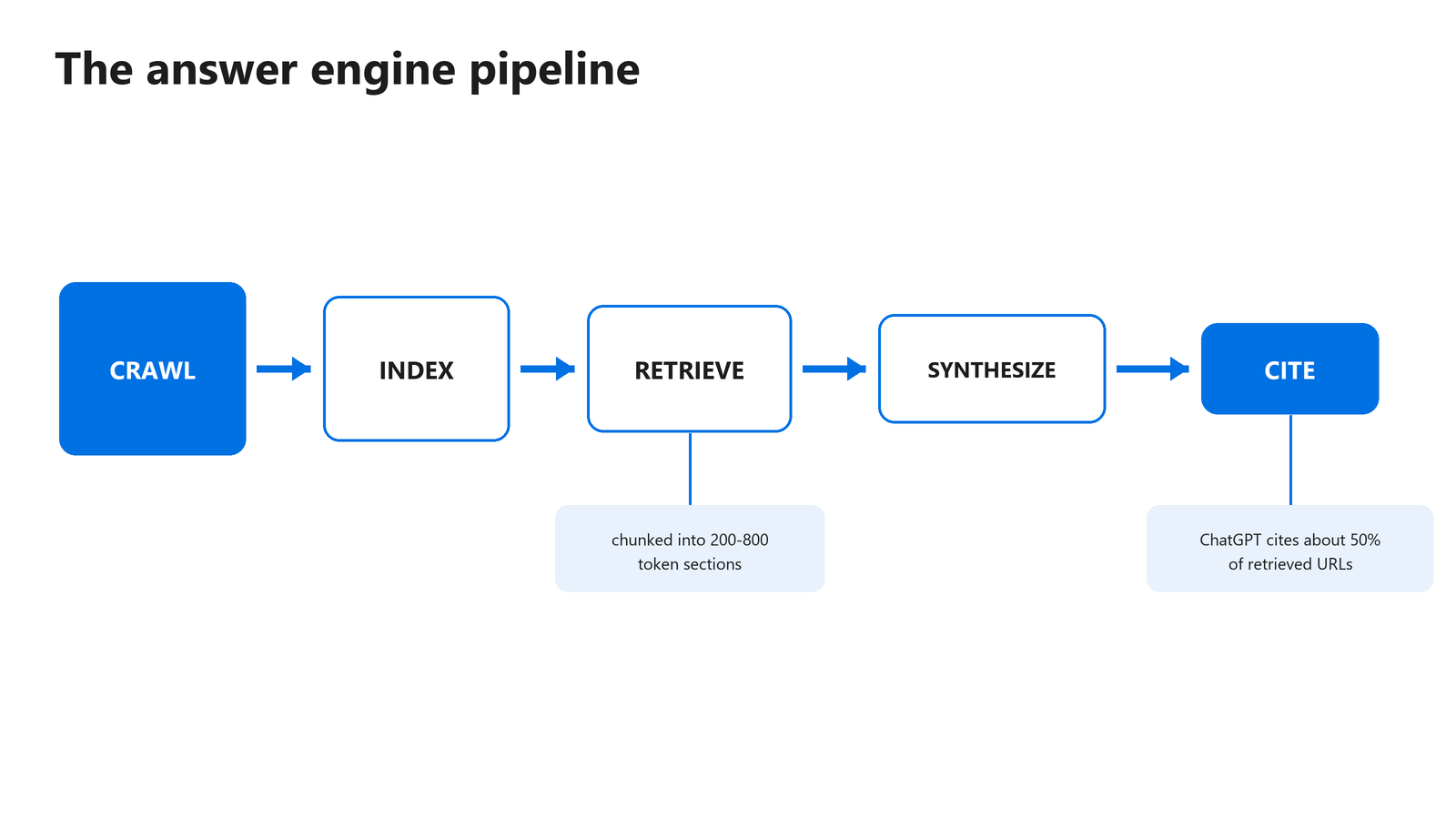
図1: ページは引用される前に、パイプラインのすべての段階を生き残らなければなりません。
クロールとインデックス
クロール段階は二者択一です。GPTBot、ClaudeBot、Google-Extended、PerplexityBot による公開コンテンツへのアクセスをブロックすれば、そのエンジンの回答から完全に外れます。クロールされると、ページは解析されて保存されます。クリーンな HTML、高速な配信、正確なメタデータが、ページがどこまで完全にインデックスへ入るかを決めます。
可視性の損失はここで始まることが最も多く、同時に最も検証しやすい段階でもあります。AI クローラーのアクセスを確認するための完全チェックリスト が、その正確な手順を解説します。
検索と統合
検索の段階でチャンキングが起こります。システムはページをセクションに分割し、それぞれをベクトルとして埋め込み、類似度でユーザーの質問とセクションを照合します。次にモデルが最も合致したチャンクを読み、統合した回答を書きます。競うのはページ全体どうしではなく、あなたの段落と他サイトの段落です。
私たちが行う監査で、優れたページが浮上しない最も多い理由は、最良の事実が9番目の段落、つまり8段落分の前置きの後に置かれていることです。リトリーバーは前半のチャンクを評価し、つなぎの文章を見つけて先へ進んでしまいます。
引用
引用は成果が出る段階で、選択的です。140万件の ChatGPT プロンプトを分析した結果、モデルが引用するのは取得した URL のおよそ半分で、引用率は情報源の種類と強く結びついていました(Ahrefs、2025年)。検索由来の結果は 88.46% の割合で引用されました。自然言語の URL スラッグを持つページは 89.78% で引用され、不透明な URL の 81.11% を上回りました。
AI にとって抽出しやすいコンテンツとは何か
抽出しやすいコンテンツは、まず答えを述べ、各段落で主語を明示し、限られたスペースに使える事実を詰め込みます。リトリーバーはセクションの最初の2文しか読まないこともあるため、その2文が役割を担います。各チャンクは単独で評価され、ページの他の部分が与える文脈なしに採点されるため、密度が高く自己完結した文章が勝ちます。
まず答えを述べる
文脈の前に、見出しの直下に答えを置きます。質問が「フランスの首都はどこか」なら、最初の文は「フランスの首都はパリです」です。補足はそのあとに続きます。100年前、ジャーナリストはこれを逆ピラミッドと呼びました。編集者が記事を末尾から削っていたからです。同じ理屈がいま、検索チャンクに当てはまります。
実際の違いを見てみましょう。弱い書き出しは事実を埋もれさせます。
hreflang タグに関しては、考慮すべき点が数多くあり、ベストプラクティスも長年にわたって進化してきました。
強い書き出しは事実を先頭に置きます。
hreflang タグは、ページがどの言語と地域を対象としているかを Google に伝えます。head 内に地域ごとに1つのタグを追加し、自己参照タグも含めます。
2つ目のほうが短く、抽出可能な事実を3つ含んでいます。Answer Extractability Checker で自分のページを試してみましょう。抽出器が実際に取り出すチャンクを正確に示してくれます。
自己完結した段落を書く
どの段落も、文脈から引き抜かれても成立しなければなりません。「それが効果的なのは」や「このアプローチがうまくいくのは」のような書き出しは避けましょう。主語を改めて明示し、段落だけで引用可能な答えとして成り立つようにします。ページを段落ごとに声に出して読んでみてください。前の段落を指す代名詞で始まる段落があれば、書き直しましょう。
つなぎを削り、シグナルを残す
つなぎの文章は、あらゆるチャンクのシグナル密度を薄めます。公開前に下書きを AI Text Humanizer に通し、前置きの文を取り除いて要となる主張を浮かび上がらせましょう。密度が高いとは、文章が濃いという意味ではありません。シグナルが濃いという意味です。1段落に1つの考え、余計な詰め物なし、事実を率直に述べることです。
引用キャプセル: 抽出しやすいコンテンツは答えを先頭に置き、各段落で主語を繰り返し、文脈から引き抜かれても成立します。これが重要なのは、検索システムが各チャンクを独立して評価し、ChatGPT は取得した URL のおよそ半分しか引用しないからです(Ahrefs、2025年)。
AI の引用はどう獲得するのか
引用は、抽出しやすいコンテンツと信頼シグナル、つまり網羅的なトピックカバレッジ、確信のある主張、引用しやすい事実、外部からの裏づけを組み合わせることで獲得できます。モデルが選ぶ時点では、すでに十数本の候補を読み終えています。あなたの役割は、ただ正しいだけでなく、その候補群の中で最も網羅的で、最も引用しやすく、最も信頼できる選択肢になることです。

図2: 従来の SERP は順位を評価します。アンサーエンジンは、数少ない引用元の一つになることを評価します。
トピックを網羅的にカバーする
薄いページは、どちらも正しい答えを含んでいても、網羅的なページに負けます。自然に一緒に属するサブトピック、用語、補足的な事実を盛り込みましょう。Topical Authority Mapper は、カバレッジが薄い箇所を示します。より充実したページを持つ競合に引用を奪われる前に、穴を埋められます。
確信を持って事実を述べる
曖昧な言い回しの文章は、具体的な主張を必要とするモデルにとって使い物になりません。「これは一般的にそうなる傾向があるかもしれません」では、モデルは引用するものがありません。答えが分かっているところは率直に述べ、例外は別に列挙しましょう。統計、バージョン番号、日付、固有名詞はいずれも引用しやすいので、盛り込みましょう。
外部からの裏づけを築く
多くのチームは引用をコンテンツの問題として捉え、そこで止まります。しかし、持続する優位は評判にあります。AI の引用を一貫して勝ち取るドメインは、モデルが他の場所ですでに参照されているのを目にしているドメインです。23万件のプロンプトと1億件超の AI 引用を13週間にわたり調査した結果、Wikipedia と Reddit が一貫して首位を占める一方、個別ドメインのシェアは月ごとに大きく揺れ動くことが分かりました(Semrush、2025年)。Reddit の ChatGPT における引用頻度は、2025年8月初旬から9月中旬にかけておよそ 60% から 10% へ落ち込みました。
何よりもまず、主力の商用ページを Citation Readiness Analyzer に通し、各ページが引用されそうか見送られそうかを確認しましょう。ページ単位の書き直しの進め方は、AI 引用に向けてサイトを最適化する方法 を参照してください。
検索チャンク向けにコンテンツを整える
ページ単位ではなくチャンク単位で整えましょう。検索システムはテキストをおよそ200〜800トークンのセクションに分割し、それぞれを独立して質問と照合します。各段落が検索の単位になるため、6番目のセクションから引き抜かれた段落が、読者が見たことのない文脈の中でも質問にきちんと答えられるように書きましょう。
密度の高い形式を使う
リストや表は、限られたスペースに使える詳細を多く収められるため、システムが短いチャンクしか取り出さないときに役立ちます。5行の比較表は1000語の文章に匹敵することがあります。リトリーバーは表全体を引用でき、モデルは1行だけを要約できるからです。密度の高い形式は、書けるなかで最もトークンあたりのシグナルが高いコンテンツです。
完全一致の質問形の見出しを使う
凝った見出しは書かないでください。ユーザーがルーターをリセットしたいなら、「Netgear Nighthawk ルーターをリセットする方法」と書き、すぐに答えます。見出しを質問にするパターンマッチは、リトリーバーが使う最も強いシグナルの一つです。Google、ChatGPT、Perplexity でその質問を自分で検索し、それぞれが表示する正確な言い回しを書き留め、勝っている表現を使いましょう。
内部の文脈を明示する
内部リンクは、サイトがどう組み合わさっているかをクローラーに伝え、その効果は積み重なります。ピラーページにリンクする新しい投稿が増えるたびに、ピラーの権威が高まります。AEO のハブを公開するなら、関連投稿はそこへ戻るリンクを張り、ハブはそれらへ向けてリンクを張るべきです。その構造は、あるトピックについてサイト内のどのページが正式な答えなのかをモデルが理解する助けにもなります。
引用キャプセル: 検索システムはページを200〜800トークンのセクションにチャンク化し、それぞれを独立してクエリと照合するため、各段落は単独で成立する必要があります。自然言語の URL スラッグを持つページは 89.78% の割合で引用され、不透明な URL の 81.11% を上回りました(Ahrefs、2025年)。
AEO と GEO の成果はどう測るのか
AEO と GEO は、技術的な健全性、抽出されやすさ、トピックカバレッジ、引用シェアという4つの軸で測ります。最も重要な指標は、気にかけているクエリに対して AI の回答にあなたのドメインが現れるかどうかであるため、キーワード順位レポートだけではもはや全体像を語れません。注意点は、引用シェアは変動が大きいため、どの計測値もスナップショットとして扱うべきだということです。
引用シェアをスナップショットとして追う
引用シェアとは、対象クエリに対して AI Overviews、ChatGPT、Perplexity、Claude の回答にあなたのドメインが現れる頻度です。数値は素早く動きます。Ahrefs は30万キーワードを対象に、AI Overview が存在する場合に上位ページのクリック率が 34.5% 低下することを計測しました(Ahrefs、2025年)。その後の追跡調査では影響がさらに拡大したと報告されており、まさにこれが単一の数値ではなく傾向を読むべき理由です。
私たち自身の毎週のスポットチェックでは、3つのエンジンで10件のクエリを回せば、1か月以内に方向性をつかむのに十分です。どのエンジンが引用したか、正確なクエリ、競合の情報源を記録します。繰り返し現れるパターンはこうです。抽出されやすさのために書き直したページは2〜4週間で引用候補に入り、手を付けなかったページは横ばいのままでした。
まず技術的な基礎を固める
引用シェアを追う前に、ページがそもそも対象になっているかを確認しましょう。1つの紛れ込んだ noindex タグ、404 を指す canonical、ブロックされた AI ユーザーエージェントが、数か月分のコンテンツ作業を帳消しにします。公開前だけでなく、定期的にこれらを監査しましょう。AI Readiness Checker はクロールアクセスとコンテンツ構造をまとめてスコア化するため、リリース前に行う単一のチェックとして最速です。
カニバリゼーションに注意する
3つのページが同じ質問に少しずつ違う形で答えていると、リトリーバーには1つの強い答えではなく、3つの中途半端な答えが見えます。そしてモデルはどれも引用せずに保留します。重複するページを1つの正式な答えに統合しましょう。私たちが検証したどの検索システムでも、1つの強いページが3つの弱いページに勝ちます。
FAQ
AEO は SEO に取って代わるのか
いいえ。AEO は SEO を拡張するもので、置き換えるものではありません。技術的な土台(クロール可能性、クリーンなメタデータ、高速な配信、内部リンク)は、両分野が依拠する共通の作業です。変わるのはコンテンツのレイヤーで、いまは順位付けだけでなく、抽出と引用に向けて書くことになります。順位は高くても答えを隠しているページは、やはり引用を取り逃します。
AI による要約は本当にトラフィックを減らすのか
情報系のクエリでは、多くの場合、はい。Google の AI による要約が表示されると、従来型の検索結果のクリック率は要約なしの 15% に対して 8% に下がり、要約内の情報源リンクをクリックしたのはユーザーのわずか 1% でした(Pew Research Center、2025年)。商用系や案内系のクエリへの影響は小さめですが、傾向は明確です。
AEO の変更が引用に反映されるまでどれくらいかかるのか
私たちの経験では、すでにクロール・インデックスされているページの抽出されやすさの修正なら2〜4週間です。選定側、つまり GEO の半分は、信頼シグナルの蓄積に依存するため時間がかかります。機械的な修正は速く、評判はゆっくりです。素早い勝ちが粘り強い作業を支えるよう、ロードマップを組み立てましょう。
コンテンツを守るために AI クローラーをブロックすべきか
意図があるときだけです。GPTBot や PerplexityBot をブロックすれば、そのエンジンの回答から完全に外れます。これはプライバシーだけでなく、可視性の判断でもあります。引用は欲しいが学習利用は避けたいなら、コンテンツポリシーの制御で検索を許可しつつ学習を制限できます。2023年からの古いブロックが静かに可視性を奪っているので、ルールは四半期ごとに見直しましょう。
今日できる最も効果の大きい変更は何か
上位10ページの書き出しを書き直し、各セクションが最初の文で答えを述べるようにすることです。これは最も安く、最も速い AEO の勝ちで、チャンク単位の検索を直接改善します。結果は Answer Extractability Checker で確認し、クロールアクセスがその成果を静かに妨げていないか検証しましょう。
次にすべきこと
アンサーエンジンはすでにあなたのページを読み込んでいます。問われるのは、そこにクリーンで引用しやすい答えを見つけるか、前置きの壁を見つけるかです。まずはスコア付きの監査を1つ実行し、技術的な基礎を固め、それから最も価値の高いページを答えから始まるように書き直しましょう。
AI Readiness Checker でサイトを診断し、クロールアクセスとコンテンツ構造を一度にスコア化しましょう。次に、このクラスター内の2つの姉妹ガイドでさらに深掘りしてください。ページ単位の書き直しの進め方は AI 引用に向けてサイトを最適化する方法、次に到来するプロトコルのレイヤーは エージェント準備 です。