Kompletny przewodnik po optymalizacji silnika odpowiedzi (AEO) i GEO
Wyszukiwanie nie jest już listą linków. Silniki wyszukiwania AI piszą bezpośrednie odpowiedzi i syntetyczne przeglądy, a ruch trafia do stron, którym ufają na tyle, by je cytować. Jeśli nie zbudujesz treści pod optymalizację silnika odpowiedzi i optymalizację silnika generatywnego, tracisz widoczność w nowej warstwie wyszukiwania.
- Wyszukiwanie AI
- AEO
- Techniczne SEO
Czym są silniki odpowiedzi i dlaczego zmieniają SEO?
Silniki odpowiedzi czytają strony za ciebie i piszą syntetyczną odpowiedź, więc kliknięcie, które kiedyś zdobywałeś, dokonuje się teraz wewnątrz okna odpowiedzi. Ta zmiana jest mierzalna. Gdy pojawiło się podsumowanie AI Google, użytkownicy klikali tradycyjny wynik tylko podczas 8% wizyt, w porównaniu z 15% bez podsumowania (Pew Research Center, 2025).
Przez dwie dekady umowa była prosta. Wpisywałeś pytanie, dostawałeś dziesięć linków i sam wykonywałeś lekturę. Wyszukiwarka pobierała dokumenty. Ty syntetyzowałeś odpowiedź. Ta praca się przemieściła.
Teraz Google AI Overviews, Perplexity i ChatGPT Search czytają wiele stron, rozstrzygają sprzeczności i same piszą odpowiedź. Twoja witryna staje się cytowaniem na dole albo zostaje pominięta. Skala jest realna: pod koniec 2025 roku ChatGPT przekroczył 800 milionów aktywnych użytkowników tygodniowo (Fortune, 2025).
Ten przewodnik jest węzłem dla wszystkiego, co następuje dalej. Omawia, jak działają silniki odpowiedzi, co czyni stronę wyodrębnialną, jak wybierane są cytowania, jaki potok wyszukiwania kryje się pod tym wszystkim oraz jak mierzyć, czy twoja praca się opłaca. Zacznij od przepuszczenia witryny przez AI Readiness Checker, aby ocenić, na jakim etapie jesteś dzisiaj.
Najważniejsze wnioski
- AEO dotyczy wyodrębnialności (czy model potrafi wyciągnąć ze strony czysty fakt), a GEO dotyczy selekcji (czy ufa ci na tyle, by cię zacytować). Potrzebujesz obu.
- Gdy pojawia się podsumowanie AI, wskaźnik kliknięć w tradycyjny wynik spada do 8% wobec 15% bez podsumowania (Pew Research Center, 2025).
- Dodanie cytowań, cytatów i statystyk może podnieść widoczność źródła w odpowiedziach generatywnych nawet o 40% (Aggarwal i in., KDD 2024).
- Pisz pod fragment, nie pod stronę. Każdy akapit jest jednostką wyszukiwania, więc musi bronić się samodzielnie.
- Udział w cytowaniach jest zmienny z miesiąca na miesiąc, więc traktuj każdy pojedynczy procent jako migawkę, a nie punkt odniesienia.
Czym AEO różni się od GEO
AEO i GEO to dwie połowy jednego potoku, a nie synonimy. AEO to mechaniczna praca polegająca na uczynieniu faktu wyodrębnialnym w jednym przebiegu. GEO to praca nad reputacją, dzięki której stajesz się źródłem, któremu model ufa na tyle, by je zacytować. Strona może być doskonale wyodrębnialna, a i tak zostać pominięta, więc potrzebujesz obu, właśnie w tej kolejności.
Pomyśl o tym jak o sekwencji „przeczytaj, potem wybierz”. Retriever musi najpierw czysto przeczytać twoją stronę, zanim model wybierze ciebie zamiast konkurenta.
Optymalizacja silnika odpowiedzi: wyodrębnialność
Optymalizacja silnika odpowiedzi stawia jedno pytanie: czy model potrafi przeczytać twoją stronę i wyciągnąć z niej czysty, cytowalny fakt? Stare SEO nagradzało długie wstępy i narracyjne rozgrzewki. AEO je karze, bo retriever dzieli stronę na fragmenty po kilkaset tokenów i ocenia każdy fragment osobno. Fragment otwierający się słowami „Zanim przejdziemy do rzeczy” przegrywa z fragmentem, który otwiera się odpowiedzią.
To problem, który możesz naprawić w jedno popołudnie. Przeprowadź audyt strony, przepisz wstęp, zrestrukturyzuj nagłówki, zmierz ponownie. Praca mechaniczna, szybka informacja zwrotna.
Optymalizacja silnika generatywnego: selekcja
Optymalizacja silnika generatywnego stawia trudniejsze pytanie: gdy retriever pobierze już kilkanaście stron kandydujących, czyim faktom model zaufa? GEO to praca nad byciem źródłem, po które model sięga, a nie tym, które pomija. Pierwotne badanie akademickie, które nadało nazwę temu obszarowi, wykazało, że metody GEO (dodawanie cytowań, cytatów i statystyk) mogą podnieść widoczność źródła w odpowiedziach generatywnych nawet o 40% (Aggarwal i in., KDD 2024).
Selekcję zdobywa się wolniej. Zupełnie nowa witryna z bezbłędnym AEO wciąż musi zbudować sygnały zaufania, które wprowadzą ją do puli cytowań danego modelu.
Kapsuła cytowania: Optymalizacja silnika odpowiedzi decyduje o tym, czy model potrafi wyodrębnić cytowalny fakt ze strony w jednym przebiegu, podczas gdy optymalizacja silnika generatywnego decyduje o tym, czy model ufa ci na tyle, by go zacytować. Liczą się obie: akademickie badanie GEO wykazało, że metody te mogą podnieść widoczność źródła nawet o 40% (Aggarwal i in., KDD 2024).
Jak działa potok wyszukiwania silnika odpowiedzi?
Silniki odpowiedzi działają w pięcioetapowym potoku: indeksowanie robotem, indeksowanie, wyszukiwanie, synteza, cytowanie. Każdy etap filtruje to, co było wcześniej. Strona, która nie przejdzie indeksowania robotem, nigdy nie zostaje zaindeksowana, a strona, która zostaje zaindeksowana, ale nigdy nie jest pobrana, nigdy nie zostaje zacytowana. Zrozumienie, na którym etapie odpadasz, mówi dokładnie, co naprawić w pierwszej kolejności.
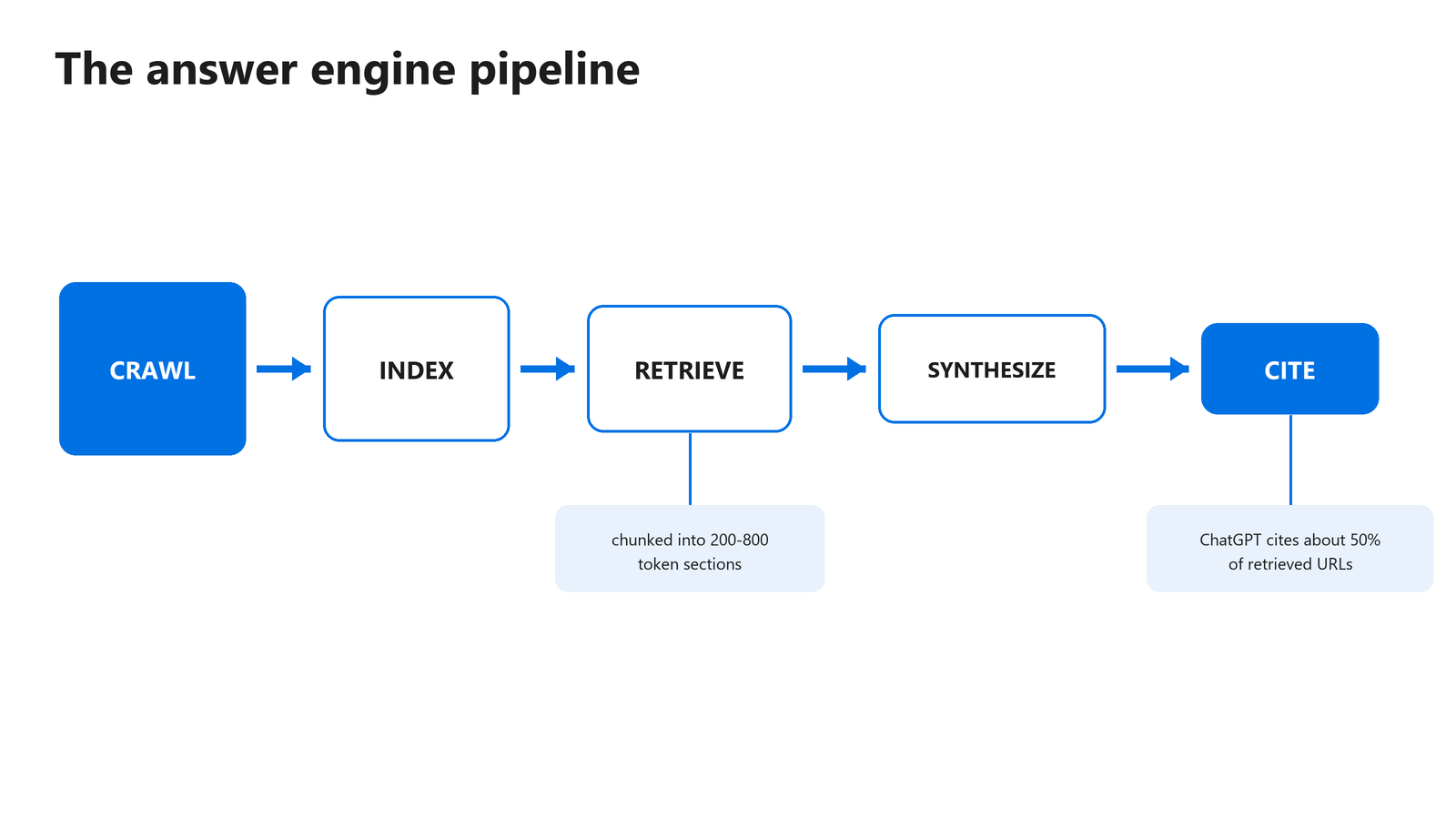
Rysunek 1: Strona musi przetrwać każdy etap potoku, zanim zostanie zacytowana.
Indeksowanie robotem i indeksowanie
Etap indeksowania robotem jest binarny. Jeśli zablokujesz GPTBot, ClaudeBot, Google-Extended lub PerplexityBot dostęp do treści publicznych, całkowicie rezygnujesz z udziału w odpowiedziach danego silnika. Po zindeksowaniu robotem twoja strona zostaje przeanalizowana i zapisana. Czysty kod HTML, szybkie dostarczanie i dokładne metadane wspólnie decydują o tym, jak kompletnie strona trafia do indeksu.
Tutaj zaczyna się większość utraconej widoczności i jest to zarazem najłatwiejszy etap do zweryfikowania. Kompletna lista kontrolna potwierdzająca dostęp robotów AI przeprowadza przez dokładne kroki.
Wyszukiwanie i synteza
Wyszukiwanie to moment, w którym następuje fragmentacja. System dzieli twoją stronę na sekcje, osadza każdą z nich jako wektor i dopasowuje sekcje do pytania użytkownika według podobieństwa. Następnie model czyta najlepiej dopasowane fragmenty i pisze syntetyczną odpowiedź. Twój akapit rywalizuje z akapitami z innych witryn, a nie całe strony z całymi stronami.
W audytach, które prowadzimy, najczęstszym powodem, dla którego mocna strona nigdy się nie pojawia, jest to, że jej najlepszy fakt leży w dziewiątym akapicie, po ośmiu akapitach budowania kontekstu. Retriever ocenia wczesne fragmenty, znajduje wypełniacz i idzie dalej.
Cytowanie
Cytowanie to etap wypłaty i jest selektywny. Analiza 1,4 miliona promptów ChatGPT wykazała, że model cytuje mniej więcej połowę adresów URL, które pobiera, przy czym wskaźnik cytowania silnie zależy od typu źródła (Ahrefs, 2025). Wyniki pochodzące z wyszukiwania były cytowane w 88,46% przypadków. Strony z adresami URL w naturalnym języku były cytowane w 89,78% przypadków, wobec 81,11% dla adresów URL nieprzejrzystych.
Co czyni treść wyodrębnialną dla AI?
Wyodrębnialna treść najpierw podaje odpowiedź, nazywa swój temat w każdym akapicie i upycha użyteczne fakty na małej przestrzeni. Retriever może przeczytać tylko dwa pierwsze zdania sekcji, więc to one dźwigają ciężar. Gęste, samowystarczalne pisanie wygrywa, bo każdy fragment jest oceniany osobno, bez kontekstu, którego dostarcza reszta strony.
Najpierw podaj odpowiedź
Umieść odpowiedź pod nagłówkiem, przed jakimkolwiek kontekstem. Jeśli pytanie brzmi „jaka jest stolica Francji”, pierwsze zdanie to „Stolicą Francji jest Paryż”. Szczegóły uzupełniające następują dalej. Dziennikarze nazwali to odwróconą piramidą sto lat temu, ponieważ redaktorzy ucinali teksty od dołu. Ta sama logika obowiązuje teraz dla fragmentów wyszukiwania.
Oto różnica w praktyce. Słaby początek grzebie fakt:
Jeśli chodzi o znaczniki hreflang, jest wiele rzeczy do rozważenia, a najlepsze praktyki ewoluowały na przestrzeni lat.
Mocny początek prowadzi nim:
Znaczniki hreflang mówią Google, na jaki język i region celuje strona. Dodaj jeden znacznik na region w nagłówku, w tym znacznik samoodwołujący się.
Druga wersja jest krótsza i zawiera trzy wyodrębnialne fakty. Sprawdź własne strony za pomocą Answer Extractability Checker, który wskazuje dokładnie te fragmenty, które ekstraktor faktycznie wyciągnie.
Pisz samowystarczalne akapity
Każdy akapit powinien przetrwać wyrwanie z kontekstu. Unikaj otwarć w rodzaju „Jest skuteczne, ponieważ” albo „To podejście sprawdza się, gdy”. Nazwij temat ponownie, aby akapit stał samodzielnie jako cytowalna odpowiedź. Przeczytaj stronę na głos, akapit po akapicie. Jeśli któryś zaczyna się od zaimka odsyłającego do akapitu powyżej, przepisz go.
Wytnij wypełniacz, zostaw sygnał
Wypełniacz rozcieńcza gęstość sygnału każdego fragmentu. Zanim opublikujesz, przepuść wersję roboczą przez AI Text Humanizer, aby usunąć zdania rozgrzewkowe i odsłonić nośne tezy. Gęste nie znaczy gęsta proza. Znaczy gęsty sygnał: jeden pomysł na akapit, żadnego wypełniacza i fakt wyrażony wprost.
Kapsuła cytowania: Wyodrębnialna treść prowadzi odpowiedzią, powtarza temat w każdym akapicie i przetrwa wyrwanie z kontekstu. Ma to znaczenie, bo systemy wyszukiwania oceniają każdy fragment niezależnie, a ChatGPT cytuje tylko około połowy pobieranych adresów URL (Ahrefs, 2025).
Jak zdobywać cytowania w AI?
Cytowania zdobywasz, łącząc wyodrębnialną treść z sygnałami zaufania: pełnym pokryciem tematu, pewnymi tezami, łatwymi do zacytowania faktami i zewnętrzną walidacją. Zanim model dokona wyboru, przeczytał już kilkanaście kandydatów. Twoim zadaniem jest być najbardziej kompletną, najbardziej cytowalną i najbardziej wiarygodną opcją w tym zestawie, a nie tylko poprawną.

Rysunek 2: Klasyczny wynik wyszukiwania nagradza pozycję w rankingu. Silnik odpowiedzi nagradza bycie jednym z kilku cytowanych źródeł.
Pokryj temat w całości
Cienkie strony przegrywają z kompleksowymi, nawet gdy obie zawierają poprawną odpowiedź. Uwzględnij podtematy, terminy i fakty uzupełniające, które naturalnie do siebie pasują. Topical Authority Mapper pokazuje, gdzie twoje pokrycie jest cienkie, abyś mógł uzupełnić luki, zanim cytowanie zgarnie konkurent z pełniejszą stroną.
Podawaj fakty z pewnością
Asekuracyjne pisanie czyni treść mniej użyteczną dla modelu, który potrzebuje konkretnej tezy. „To może na ogół zdarzać się w tych przypadkach” nie daje modelowi nic do zacytowania. Tam, gdzie znasz odpowiedź, powiedz to wprost, a wyjątki wymień osobno. Statystyki, numery wersji, daty i nazwane podmioty są łatwe do zacytowania, więc je umieszczaj.
Buduj zewnętrzną walidację
Większość zespołów traktuje cytowanie jako problem treści i na tym poprzestaje, ale trwałą przewagą jest reputacja. Domeny, które konsekwentnie wygrywają cytowania w AI, to te, do których modele już widzą odwołania gdzie indziej. 13-tygodniowe badanie 230 000 promptów i ponad 100 milionów cytowań AI wykazało, że Wikipedia i Reddit prowadzą konsekwentnie, podczas gdy udział poszczególnych domen mocno waha się z miesiąca na miesiąc (Semrush, 2025). Częstotliwość cytowania Reddita w ChatGPT spadła z około 60% do 10% między początkiem sierpnia a połową września 2025 roku.
Zanim zajmiesz się czymkolwiek innym, przepuść najważniejsze strony komercyjne przez Citation Readiness Analyzer, aby sprawdzić, czy każda z nich ma szansę zostać zacytowana, czy pominięta. Proces przepisywania strona po stronie opisuje jak zoptymalizować witrynę pod cytowania AI.
Formatowanie treści pod fragmenty wyszukiwania
Formatuj pod fragment, nie pod stronę. Systemy wyszukiwania dzielą tekst na sekcje liczące mniej więcej 200 do 800 tokenów i niezależnie dopasowują każdą do pytania. Każdy akapit jest jednostką wyszukiwania, więc pisz tak, aby akapit wyciągnięty z szóstej sekcji wciąż dobrze odpowiadał na pytanie w kontekście, którego czytelnik nigdy nie widział.
Używaj gęstych formatów
Listy i tabele mieszczą wiele użytecznych szczegółów na małej przestrzeni, co pomaga, gdy system pobiera tylko krótki fragment. Pięciowierszowa tabela porównawcza może być warta tysiąca słów prozy, bo retriever potrafi zacytować całą tabelę, a model podsumować pojedynczy wiersz. Gęste formaty to treść o najwyższym stosunku sygnału do tokena, jaką możesz napisać.
Używaj dokładnie dopasowanych nagłówków w kształcie pytań
Nie pisz sprytnych nagłówków. Jeśli użytkownik chce zresetować router, napisz „Jak zresetować router Netgear Nighthawk”, a potem od razu odpowiedz. Dopasowywanie wzorca nagłówek-jako-pytanie to jeden z najsilniejszych sygnałów, których używają retrievery. Wyszukaj pytanie samodzielnie w Google, ChatGPT i Perplexity, zapisz dokładne sformułowanie, które wyświetla każdy z nich, i użyj zwycięskiej wersji.
Czyń kontekst wewnętrzny jawnym
Linki wewnętrzne mówią robotom, jak twoja witryna łączy się w całość, a ich efekt kumuluje się. Każdy nowy wpis, który linkuje do strony filarowej, podnosi autorytet filaru. Jeśli publikujesz węzeł poświęcony AEO, powiązane wpisy powinny do niego odsyłać, a węzeł powinien odsyłać do nich. Taka struktura pomaga też modelowi zrozumieć, która strona w twojej witrynie jest kanoniczną odpowiedzią na dany temat.
Kapsuła cytowania: Systemy wyszukiwania dzielą strony na sekcje liczące 200 do 800 tokenów i niezależnie dopasowują każdą do zapytania, więc każdy akapit musi bronić się samodzielnie. Strony z adresami URL w naturalnym języku były cytowane w 89,78% przypadków, wobec 81,11% dla adresów URL nieprzejrzystych (Ahrefs, 2025).
Jak mierzyć skuteczność AEO i GEO?
Skuteczność AEO i GEO mierzysz na czterech torach: kondycja techniczna, wyodrębnialność, pokrycie tematu i udział w cytowaniach. Raport o pozycjach słów kluczowych nie opowiada już całej historii, bo najważniejszym wskaźnikiem jest to, czy twoja domena pojawia się w odpowiedziach AI dla zapytań, na których ci zależy. Jest jednak haczyk: udział w cytowaniach jest zmienny, więc traktuj każdy odczyt jako migawkę.
Śledź udział w cytowaniach jako migawkę
Udział w cytowaniach to częstotliwość, z jaką twoja domena pojawia się w AI Overviews oraz odpowiedziach ChatGPT, Perplexity i Claude dla twoich docelowych zapytań. Liczby zmieniają się szybko. Ahrefs zmierzył o 34,5% niższy wskaźnik klikalności dla strony z najwyższej pozycji, gdy obecny jest AI Overview, na próbie 300 000 słów kluczowych (Ahrefs, 2025). Późniejsza kontynuacja podała, że wpływ jeszcze się pogłębił, co jest dokładnie powodem, dla którego odczytujesz trendy, a nie pojedyncze liczby.
W naszych cotygodniowych kontrolach wyrywkowych dziesięć zapytań przepuszczonych przez trzy silniki wystarcza, by w ciągu miesiąca wskazać kierunek. Notujemy, który silnik nas zacytował, dokładne zapytanie oraz konkurujące źródła. Powtarza się ten sam wzorzec: strony, które przepisaliśmy pod wyodrębnialność, wchodziły do puli cytowań w ciągu dwóch do czterech tygodni, podczas gdy strony nietknięte pozostawały bez zmian.
Najpierw przypilnuj podstaw technicznych
Zanim zaczniesz gonić za udziałem w cytowaniach, potwierdź, że strona w ogóle się kwalifikuje. Jeden zabłąkany znacznik noindex, kanoniczny wskazujący na błąd 404 albo zablokowany agent użytkownika AI niweczy miesiące pracy nad treścią. Audytuj te elementy regularnie, nie tylko przed startem. AI Readiness Checker ocenia jednocześnie dostęp robotów i strukturę treści, więc to najszybsza pojedyncza kontrola do uruchomienia przed wydaniem.
Wypatruj kanibalizacji
Jeśli trzy strony odpowiadają na to samo pytanie nieco inaczej, retriever widzi trzy na wpół autorytatywne odpowiedzi zamiast jednej mocnej, a modele asekurują się, nie cytując żadnej. Skonsoliduj nakładające się strony w jedną kanoniczną odpowiedź. Jedna mocna strona bije trzy słabe w każdym systemie wyszukiwania, jaki przetestowaliśmy.
FAQ
Czy AEO zastępuje SEO?
Nie. AEO rozszerza SEO, nie zastępuje go. Fundament techniczny (indeksowalność, czyste metadane, szybkie dostarczanie, linki wewnętrzne) to ta sama praca, na której opierają się obie dyscypliny. Zmienia się warstwa treści: piszesz teraz pod wyodrębnianie i cytowanie, a nie tylko pod ranking. Strona, która dobrze się pozycjonuje, ale ukrywa swoją odpowiedź, i tak przegra cytowanie.
Czy podsumowania AI naprawdę zmniejszają mój ruch?
Często tak, w przypadku zapytań informacyjnych. Gdy pojawiło się podsumowanie AI Google, wskaźnik kliknięć w tradycyjny wynik spadł do 8% wobec 15% bez niego, a tylko 1% użytkowników kliknął link do źródła wewnątrz samego podsumowania (Pew Research Center, 2025). Zapytania komercyjne i nawigacyjne są mniej dotknięte, ale trend jest jasny.
Ile czasu zajmuje, zanim zmiany AEO pojawią się w cytowaniach?
Z naszego doświadczenia od dwóch do czterech tygodni dla poprawek wyodrębnialności na stronach, które są już zindeksowane robotem i zaindeksowane. Zyski po stronie selekcji, czyli połowa GEO, trwają dłużej, bo zależą od kumulowania sygnałów zaufania. Poprawki mechaniczne są szybkie. Reputacja jest wolna. Zaplanuj mapę drogową tak, by szybkie zwycięstwa finansowały cierpliwą pracę.
Czy powinienem blokować roboty AI, aby chronić swoją treść?
Tylko z rozmysłem. Zablokowanie GPTBota lub PerplexityBota całkowicie usuwa cię z odpowiedzi danego silnika, co jest decyzją o widoczności, a nie tylko o prywatności. Jeśli chcesz cytowań, ale nie wykorzystywania do treningu, mechanizmy zasad treści pozwalają zezwolić na wyszukiwanie przy jednoczesnym ograniczeniu treningu. Przeglądaj reguły kwartalnie, bo nieaktualne blokady z 2023 roku po cichu kosztują widoczność.
Jaka jest pojedyncza zmiana o największym wpływie, jaką mogę wprowadzić dzisiaj?
Przepisz początki swoich dziesięciu najważniejszych stron tak, aby każda sekcja podawała odpowiedź w pierwszym zdaniu. To najtańsze, najszybsze zwycięstwo AEO i bezpośrednio poprawia wyszukiwanie na poziomie fragmentu. Potwierdź wynik za pomocą Answer Extractability Checker i upewnij się, że dostęp robotów po cichu nie blokuje tych zysków.
Co robić dalej
Silniki odpowiedzi już czytają twoje strony. Pytanie brzmi, czy znajdują czystą, cytowalną odpowiedź, czy ścianę tekstu rozgrzewkowego. Zacznij od jednego punktowanego audytu, napraw podstawy techniczne, a potem przepisz swoje najcenniejsze strony tak, by prowadziły odpowiedzią.
Przepuść witrynę przez AI Readiness Checker, aby w jednym przebiegu ocenić dostęp robotów i strukturę treści. Następnie zejdź głębiej z dwoma siostrzanymi przewodnikami z tego klastra: jak zoptymalizować witrynę pod cytowania AI opisuje proces przepisywania strona po stronie, a gotowość agenta omawia warstwę protokołu, która nadchodzi w następnej kolejności.