उत्तर इंजन अनुकूलन (AEO) और GEO के लिए संपूर्ण मार्गदर्शिका
खोज अब लिंक की सूची नहीं रही। एआई खोज इंजन सीधे उत्तर और संश्लेषित अवलोकन लिखते हैं, और ट्रैफ़िक उन्हीं पृष्ठों पर जाता है जिन पर वे उद्धृत करने लायक भरोसा करते हैं। यदि आप उत्तर इंजन अनुकूलन और जनरेटिव इंजन अनुकूलन के लिए अपनी सामग्री नहीं बनाते, तो आप नई खोज परत में दृश्यता खो देते हैं।
- एआई खोज
- AEO
- तकनीकी SEO
उत्तर इंजन क्या हैं और वे SEO को क्यों बदल देते हैं?
उत्तर इंजन आपके लिए पृष्ठ पढ़ते हैं और एक संश्लेषित जवाब लिख देते हैं, इसलिए वह क्लिक जो पहले आप अर्जित करते थे, अब उत्तर बॉक्स के भीतर ही हो जाता है। यह बदलाव मापने योग्य है। जब किसी Google AI सारांश ने जगह बनाई, तब उपयोगकर्ताओं ने केवल 8% बार किसी पारंपरिक परिणाम पर क्लिक किया, जबकि बिना सारांश के यह दर 15% थी (Pew Research Center, 2025)।
दो दशकों तक सौदा सीधा था। आप एक प्रश्न टाइप करते, दस लिंक पाते, और पढ़ने का काम खुद करते। इंजन दस्तावेज़ पुनर्प्राप्त करता था। उत्तर आप जोड़ते थे। अब वह श्रम स्थानांतरित हो गया है।
अब Google’s AI Overviews, Perplexity, और ChatGPT Search कई पृष्ठ पढ़ते हैं, विरोधों को सुलझाते हैं, और उत्तर खुद लिख देते हैं। आपकी साइट नीचे एक उद्धरण भर बनकर रह जाती है, या फिर छूट जाती है। पैमाना वास्तविक है: ChatGPT ने 2025 के उत्तरार्ध में 80 करोड़ साप्ताहिक सक्रिय उपयोगकर्ताओं का आंकड़ा पार कर लिया (Fortune, 2025)।
यह मार्गदर्शिका आगे आने वाली हर बात का केंद्र है। यह बताती है कि उत्तर इंजन कैसे काम करते हैं, किसी पृष्ठ को निकालने योग्य क्या बनाता है, उद्धरण कैसे चुने जाते हैं, इन सबके नीचे की पुनर्प्राप्ति पाइपलाइन कैसी है, और यह कैसे मापें कि आपका काम फल दे रहा है या नहीं। शुरुआत अपनी साइट को AI Readiness Checker से चलाकर करें और देखें कि आज आप कहाँ खड़े हैं।
मुख्य बातें
- AEO निकालने की क्षमता के बारे में है (क्या कोई मॉडल आपके पृष्ठ से एक साफ़ तथ्य खींच सकता है) और GEO चयन के बारे में है (क्या वह आप पर उद्धृत करने लायक भरोसा करता है)। आपको दोनों चाहिए।
- जब कोई AI सारांश दिखता है, तो पारंपरिक परिणाम पर क्लिक दर 15% की तुलना में गिरकर 8% रह जाती है (Pew Research Center, 2025)।
- उद्धरण, उद्धृत वाक्य और आँकड़े जोड़ने से किसी स्रोत की जनरेटिव उत्तरों में दृश्यता 40% तक बढ़ सकती है (Aggarwal et al., KDD 2024)।
- पृष्ठ के लिए नहीं, खंड के लिए लिखें। हर अनुच्छेद पुनर्प्राप्ति इकाई है, इसलिए उसे अपने दम पर खड़ा होना चाहिए।
- उद्धरण हिस्सेदारी महीने दर महीने अस्थिर रहती है, इसलिए किसी भी एक प्रतिशत को मानक नहीं, एक झलक मानें।
AEO, GEO से कैसे अलग है
AEO और GEO एक ही पाइपलाइन के दो हिस्से हैं, पर्यायवाची नहीं। AEO वह यांत्रिक काम है जो किसी तथ्य को एक ही बार में निकालने योग्य बनाता है। GEO वह प्रतिष्ठा का काम है जिससे आप वह स्रोत बनते हैं जिस पर मॉडल उद्धृत करने लायक भरोसा करता है। कोई पृष्ठ पूरी तरह निकालने योग्य होकर भी छूट सकता है, इसलिए आपको दोनों चाहिए, और इसी क्रम में।
इसे ऐसे समझें: पहले पढ़ना, फिर चुनना। मॉडल आपको किसी प्रतिस्पर्धी पर तरजीह देकर चुने, उससे पहले पुनर्प्राप्तिकर्ता को आपका पृष्ठ साफ़-साफ़ पढ़ना ही होता है।
उत्तर इंजन अनुकूलन: निकालने की क्षमता
उत्तर इंजन अनुकूलन एक ही सवाल पूछता है: क्या कोई मॉडल आपका पृष्ठ पढ़कर उसमें से एक साफ़, उद्धृत करने योग्य तथ्य खींच सकता है? पुराने SEO ने लंबे परिचय और कथात्मक भूमिका को पुरस्कृत किया। AEO उन्हें दंडित करता है, क्योंकि पुनर्प्राप्तिकर्ता आपके पृष्ठ को कुछ सौ टोकन के खंडों में तोड़ता है और हर खंड को अलग से रैंक करता है। “इस पर आने से पहले” जैसी पंक्ति से शुरू होने वाला खंड उस खंड से हार जाता है जो उत्तर से शुरू होता है।
यह ऐसी समस्या है जिसे आप एक दोपहर में ठीक कर सकते हैं। पृष्ठ का ऑडिट करें, परिचय फिर से लिखें, शीर्षकों का पुनर्गठन करें, और फिर से मापें। यांत्रिक काम, तेज़ प्रतिक्रिया।
जनरेटिव इंजन अनुकूलन: चयन
जनरेटिव इंजन अनुकूलन कठिन सवाल पूछता है: जब पुनर्प्राप्तिकर्ता एक दर्जन उम्मीदवार पृष्ठ ला चुका हो, तो मॉडल किसके तथ्यों पर भरोसा करता है? GEO वही स्रोत बनने का काम है जिसकी ओर मॉडल हाथ बढ़ाता है, न कि जिसे वह अनदेखा करता है। इस क्षेत्र को नाम देने वाले मूल शैक्षणिक अध्ययन ने दिखाया कि GEO विधियाँ (उद्धरण, उद्धृत वाक्य और आँकड़े जोड़ना) किसी स्रोत की जनरेटिव प्रतिक्रियाओं में दृश्यता को 40% तक बढ़ा सकती हैं (Aggarwal et al., KDD 2024)।
चयन अर्जित करना धीमा होता है। बेहतरीन AEO वाली बिल्कुल नई साइट को भी वे भरोसे के संकेत बनाने पड़ते हैं जो उसे किसी मॉडल के उद्धरण पूल में पहुँचाते हैं।
उद्धरण कैप्सूल: उत्तर इंजन अनुकूलन यह तय करता है कि कोई मॉडल आपके पृष्ठ से एक ही बार में उद्धृत करने योग्य तथ्य निकाल सकता है या नहीं, जबकि जनरेटिव इंजन अनुकूलन यह तय करता है कि मॉडल आप पर उद्धृत करने लायक भरोसा करता है या नहीं। दोनों मायने रखते हैं: शैक्षणिक GEO अध्ययन ने पाया कि ये विधियाँ स्रोत की दृश्यता 40% तक बढ़ा सकती हैं (Aggarwal et al., KDD 2024)।
उत्तर इंजन की पुनर्प्राप्ति पाइपलाइन कैसे काम करती है?
उत्तर इंजन पाँच चरणों की एक पाइपलाइन चलाते हैं: crawl, अनुक्रमण, पुनर्प्राप्ति, संश्लेषण, उद्धरण। हर चरण उससे पहले वाले को छानता है। जो पृष्ठ crawl में विफल रहता है वह कभी अनुक्रमित नहीं होता, और जो पृष्ठ अनुक्रमित तो होता है पर कभी पुनर्प्राप्त नहीं होता वह कभी उद्धृत नहीं होता। आप कहाँ छूट रहे हैं, यह समझना आपको ठीक-ठीक बता देता है कि पहले क्या ठीक करना है।
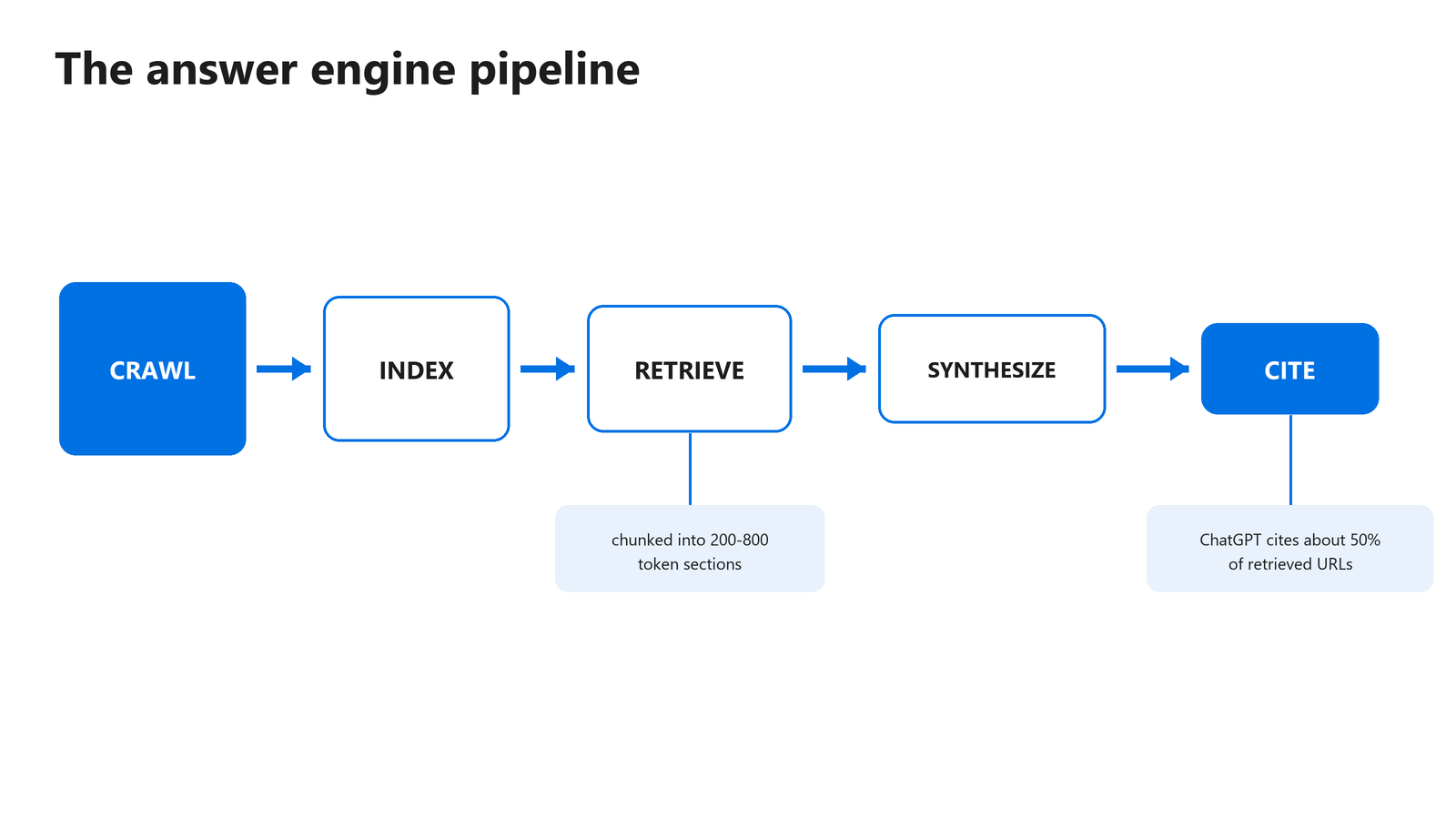
चित्र 1: उद्धृत होने से पहले किसी पृष्ठ को पाइपलाइन के हर चरण से बचकर निकलना होता है।
Crawl और अनुक्रमण
crawl चरण द्विआधारी है। यदि आप GPTBot, ClaudeBot, Google-Extended, या PerplexityBot को अपनी सार्वजनिक सामग्री से रोकते हैं, तो आप उस इंजन के उत्तरों से पूरी तरह बाहर हो जाते हैं। एक बार crawl होने के बाद, आपका पृष्ठ पार्स होकर संग्रहीत हो जाता है। साफ़ HTML, तेज़ डिलीवरी और सटीक मेटाडेटा, ये सब तय करते हैं कि पृष्ठ अनुक्रमणिका में कितनी पूर्णता से प्रवेश करता है।
अधिकांश खोई हुई दृश्यता यहीं से शुरू होती है, और यह सत्यापित करने का सबसे आसान चरण भी यही है। AI crawler पहुँच की पुष्टि की संपूर्ण चेकलिस्ट ठीक-ठीक हर कदम बताती है।
पुनर्प्राप्ति और संश्लेषण
पुनर्प्राप्ति वहीं होती है जहाँ खंडन (chunking) होता है। सिस्टम आपके पृष्ठ को खंडों में बाँटता है, हर एक को एक वेक्टर के रूप में एम्बेड करता है, और समानता के आधार पर खंडों को उपयोगकर्ता के प्रश्न से मिलाता है। फिर मॉडल सबसे अधिक मिलते-जुलते खंड पढ़ता है और एक संश्लेषित उत्तर लिखता है। आपका अनुच्छेद पूरे पृष्ठ के बजाय दूसरी साइटों के अनुच्छेदों से प्रतिस्पर्धा करता है।
हमारे किए ऑडिट में, किसी मज़बूत पृष्ठ के कभी सामने न आने का सबसे आम कारण यही होता है कि उसका सबसे अच्छा तथ्य नौवें अनुच्छेद में, आठ अनुच्छेदों की भूमिका के बाद रहता है। पुनर्प्राप्तिकर्ता शुरुआती खंडों को अंक देता है, भराव पाता है, और आगे बढ़ जाता है।
उद्धरण
उद्धरण ही प्रतिफल वाला चरण है, और यह चयनात्मक है। 14 लाख ChatGPT प्रॉम्प्ट के एक विश्लेषण में पाया गया कि मॉडल अपने पुनर्प्राप्त किए गए URL में से लगभग आधे को उद्धृत करता है, और यह उद्धरण दर स्रोत के प्रकार से गहराई से जुड़ी है (Ahrefs, 2025)। खोज-स्रोत वाले परिणाम 88.46% बार उद्धृत हुए। प्राकृतिक-भाषा वाले URL slug वाले पृष्ठ 89.78% बार उद्धृत हुए, जबकि अस्पष्ट URL केवल 81.11% बार।
सामग्री को AI के लिए निकालने योग्य क्या बनाता है?
निकालने योग्य सामग्री पहले उत्तर बताती है, हर अनुच्छेद में अपने विषय का नाम लेती है, और कम जगह में काम के तथ्य भर देती है। पुनर्प्राप्तिकर्ता किसी खंड के केवल पहले दो वाक्य ही पढ़ सकता है, इसलिए सारा बोझ वही वाक्य उठाते हैं। सघन, स्व-निहित लेखन जीतता है क्योंकि हर खंड को अकेले रैंक किया जाता है, उस संदर्भ के बिना जो आपका बाकी पृष्ठ देता है।
पहले उत्तर बताएँ
उत्तर को शीर्षक के नीचे, किसी भी संदर्भ से पहले रखें। यदि प्रश्न है “फ़्रांस की राजधानी क्या है,” तो पहला वाक्य है “फ़्रांस की राजधानी पेरिस है।” सहायक विवरण उसके बाद आता है। पत्रकारों ने एक सदी पहले इसे उल्टा पिरामिड कहा था, क्योंकि संपादक खबरों को नीचे से काटते थे। वही तर्क अब पुनर्प्राप्ति खंडों पर लागू होता है।
व्यवहार में अंतर यहाँ है। एक कमज़ोर शुरुआत तथ्य को दबा देती है:
जहाँ तक hreflang टैग की बात है, ध्यान देने योग्य कई बातें हैं, और सर्वोत्तम प्रथाएँ वर्षों में विकसित हुई हैं।
एक मज़बूत शुरुआत उसी से आगे बढ़ती है:
hreflang टैग Google को बताते हैं कि कोई पृष्ठ किस भाषा और क्षेत्र को लक्षित करता है। हेड में प्रति क्षेत्र एक टैग जोड़ें, जिसमें एक स्व-संदर्भित टैग भी शामिल हो।
दूसरा संस्करण छोटा है और इसमें तीन निकालने योग्य तथ्य हैं। अपने पृष्ठों को Answer Extractability Checker से जाँचें, जो ठीक-ठीक उन खंडों को इंगित करता है जिन्हें कोई एक्सट्रैक्टर वास्तव में खींचेगा।
स्व-निहित अनुच्छेद लिखें
हर अनुच्छेद को संदर्भ से बाहर खींचे जाने पर भी टिके रहना चाहिए। “यह प्रभावी है क्योंकि” या “यह तरीका तब अच्छा काम करता है जब” जैसी शुरुआत से बचें। विषय का नाम फिर से लें ताकि अनुच्छेद एक उद्धृत करने योग्य उत्तर के रूप में अकेला खड़ा रहे। अपना पृष्ठ अनुच्छेद-दर-अनुच्छेद ज़ोर से पढ़ें। यदि कोई अनुच्छेद ऐसे सर्वनाम से शुरू होता है जो ऊपर वाले अनुच्छेद की ओर इशारा करता है, तो उसे फिर से लिखें।
भराव हटाएँ, संकेत रखें
भराव हर खंड के संकेत घनत्व को पतला कर देता है। प्रकाशित करने से पहले मसौदे को AI Text Humanizer से चलाएँ ताकि भूमिका वाले वाक्य हट जाएँ और भार उठाने वाले दावे सामने आ जाएँ। सघन का मतलब घना गद्य नहीं है। इसका मतलब है सघन संकेत: प्रति अनुच्छेद एक विचार, कोई भराई नहीं, और तथ्य सीधे-सादे ढंग से कहा गया।
उद्धरण कैप्सूल: निकालने योग्य सामग्री उत्तर से शुरू होती है, हर अनुच्छेद में विषय दोहराती है, और संदर्भ से बाहर खींचे जाने पर भी टिकती है। यह इसलिए मायने रखता है क्योंकि पुनर्प्राप्ति सिस्टम हर खंड को स्वतंत्र रूप से रैंक करते हैं, और ChatGPT अपने पुनर्प्राप्त URL में से केवल लगभग आधे को ही उद्धृत करता है (Ahrefs, 2025)।
आप AI उद्धरण कैसे अर्जित करते हैं?
आप निकालने योग्य सामग्री को भरोसे के संकेतों के साथ जोड़कर उद्धरण अर्जित करते हैं: पूरा सामयिक कवरेज, आत्मविश्वासी दावे, आसानी से उद्धृत होने वाले तथ्य, और बाहरी सत्यापन। जब तक मॉडल चुनाव करता है, तब तक वह एक दर्जन उम्मीदवार पढ़ चुका होता है। आपका काम है उस समूह में सबसे संपूर्ण, सबसे उद्धरण योग्य और सबसे विश्वसनीय विकल्प बनना, केवल एक सही विकल्प भर नहीं।

चित्र 2: क्लासिक SERP रैंकिंग को पुरस्कृत करता है। उत्तर इंजन कुछ चुनिंदा उद्धृत स्रोतों में से एक होने को पुरस्कृत करता है।
विषय को पूरी तरह कवर करें
पतले पृष्ठ व्यापक पृष्ठों से हार जाते हैं, भले ही दोनों में सही उत्तर हो। उन उपविषयों, शब्दों और सहायक तथ्यों को शामिल करें जो स्वाभाविक रूप से साथ जुड़े होते हैं। Topical Authority Mapper दिखाता है कि आपका कवरेज कहाँ पतला है, ताकि आप अंतराल भर सकें इससे पहले कि किसी पूर्ण पृष्ठ वाला प्रतिस्पर्धी वह उद्धरण ले उड़े।
तथ्यों को आत्मविश्वास से बताएँ
बचाव भरा लेखन सामग्री को उस मॉडल के लिए कम उपयोगी बना देता है जिसे एक ठोस दावा चाहिए। “यह आम तौर पर ऐसा हो सकता है” मॉडल को उद्धृत करने लायक कुछ नहीं देता। जहाँ आप उत्तर जानते हैं, उसे साफ़-साफ़ कहें, फिर अपवादों को अलग से सूचीबद्ध करें। आँकड़े, संस्करण संख्याएँ, तिथियाँ और नामित इकाइयाँ, ये सब आसानी से उद्धृत होती हैं, इसलिए इन्हें शामिल करें।
बाहरी सत्यापन बनाएँ
अधिकांश टीमें उद्धरण को एक सामग्री समस्या मानकर वहीं रुक जाती हैं, पर टिकाऊ बढ़त प्रतिष्ठा से आती है। जो डोमेन लगातार AI उद्धरण जीतते हैं, वे वही होते हैं जिन्हें मॉडल पहले से कहीं और संदर्भित देखते हैं। 2,30,000 प्रॉम्प्ट और 10 करोड़ से अधिक AI उद्धरणों के 13-सप्ताह के अध्ययन में पाया गया कि Wikipedia और Reddit लगातार आगे रहते हैं, जबकि अलग-अलग डोमेन की हिस्सेदारी महीने दर महीने तेज़ी से घटती-बढ़ती है (Semrush, 2025)। अगस्त की शुरुआत और सितंबर 2025 के मध्य के बीच ChatGPT में Reddit की उद्धरण आवृत्ति लगभग 60% से गिरकर 10% रह गई।
किसी भी और चीज़ से पहले, अपने शीर्ष वाणिज्यिक पृष्ठों को Citation Readiness Analyzer से चलाएँ ताकि देख सकें कि हर पृष्ठ के उद्धृत होने की संभावना है या छूटने की। पृष्ठ-दर-पृष्ठ पुनर्लेखन प्रक्रिया के लिए, देखें अपनी साइट को AI उद्धरणों के लिए कैसे अनुकूलित करें।
पुनर्प्राप्ति खंडों के लिए सामग्री प्रारूपित करना
पृष्ठ के लिए नहीं, खंड के लिए प्रारूपित करें। पुनर्प्राप्ति सिस्टम पाठ को लगभग 200 से 800 टोकन के खंडों में बाँटते हैं और हर एक को किसी प्रश्न से स्वतंत्र रूप से मिलाते हैं। हर अनुच्छेद एक पुनर्प्राप्ति इकाई है, इसलिए ऐसे लिखें कि खंड छह से खींचा गया अनुच्छेद भी ऐसे संदर्भ में किसी प्रश्न का अच्छा उत्तर दे, जिसे पाठक ने कभी देखा ही नहीं।
सघन प्रारूपों का उपयोग करें
सूचियाँ और तालिकाएँ कम जगह में बहुत सारा काम का विवरण रखती हैं, जो तब मददगार होता है जब सिस्टम केवल एक छोटा खंड खींचता है। पाँच-पंक्ति वाली तुलना तालिका गद्य के हज़ार शब्दों के बराबर हो सकती है, क्योंकि पुनर्प्राप्तिकर्ता पूरी तालिका उद्धृत कर सकता है और मॉडल किसी एक पंक्ति का सारांश दे सकता है। सघन प्रारूप वह सामग्री हैं जिनमें प्रति-टोकन सबसे अधिक संकेत होता है।
सटीक-मिलान, प्रश्न-आकार वाले शीर्षक उपयोग करें
चतुर शीर्षक मत लिखिए। यदि कोई उपयोगकर्ता राउटर रीसेट करना चाहता है, तो “नेटगियर नाइटहॉक राउटर को कैसे रीसेट करें” लिखें, फिर तुरंत उत्तर दें। शीर्षक-को-प्रश्न जैसे पैटर्न मिलान पुनर्प्राप्तिकर्ताओं द्वारा उपयोग किए जाने वाले सबसे मज़बूत संकेतों में से एक है। प्रश्न को खुद Google, ChatGPT और Perplexity पर खोजें, हर इंजन के सामने आने वाले सटीक वाक्यांश पर ध्यान दें, और जीतने वाले संस्करण का उपयोग करें।
आंतरिक संदर्भ स्पष्ट बनाएँ
आंतरिक लिंक crawlers को बताते हैं कि आपकी साइट के हिस्से आपस में कैसे जुड़ते हैं, और इनका असर बढ़ता जाता है। आपके स्तंभ पृष्ठ से जुड़ने वाली हर नई पोस्ट स्तंभ का अधिकार बढ़ाती है। यदि आप AEO पर एक हब प्रकाशित करते हैं, तो आपकी संबंधित पोस्ट को उसकी ओर इशारा करना चाहिए, और हब को उनकी ओर। वह संरचना किसी मॉडल को यह समझने में भी मदद करती है कि आपकी साइट का कौन-सा पृष्ठ किसी विषय के लिए प्रामाणिक उत्तर है।
उद्धरण कैप्सूल: पुनर्प्राप्ति सिस्टम पृष्ठों को 200 से 800 टोकन के खंडों में बाँटते हैं और हर एक को किसी प्रश्न से स्वतंत्र रूप से मिलाते हैं, इसलिए हर अनुच्छेद को अकेले खड़ा होना चाहिए। प्राकृतिक-भाषा वाले URL slug वाले पृष्ठ 89.78% बार उद्धृत हुए, जबकि अस्पष्ट URL केवल 81.11% बार (Ahrefs, 2025)।
आप AEO और GEO प्रदर्शन कैसे मापते हैं?
आप AEO और GEO को चार पटरियों से मापते हैं: तकनीकी स्वास्थ्य, निकालने की क्षमता, सामयिक कवरेज, और उद्धरण हिस्सेदारी। एक कीवर्ड रैंक रिपोर्ट अब पूरी कहानी नहीं बताती, क्योंकि सबसे अहम मीट्रिक यह है कि आप जिन प्रश्नों की परवाह करते हैं उनके लिए आपका डोमेन AI उत्तरों में दिखता है या नहीं। पेच यह है: उद्धरण हिस्सेदारी अस्थिर है, इसलिए हर पाठ को एक झलक मानें।
उद्धरण हिस्सेदारी को एक झलक की तरह ट्रैक करें
उद्धरण हिस्सेदारी यह है कि आपके लक्षित प्रश्नों के लिए आपका डोमेन AI Overviews, ChatGPT, Perplexity और Claude के उत्तरों में कितनी बार दिखता है। आँकड़े तेज़ी से बदलते हैं। Ahrefs ने 3,00,000 कीवर्ड पर मापा कि AI Overview मौजूद होने पर शीर्ष रैंक वाले पृष्ठ की क्लिक-थ्रू दर 34.5% कम रहती है (Ahrefs, 2025)। एक बाद की रिपोर्ट में बताया गया कि असर और बढ़ गया है, और यही ठीक-ठीक वजह है कि आप रुझान पढ़ते हैं, अकेले आँकड़े नहीं।
हमारी अपनी साप्ताहिक स्पॉट जाँचों में, तीन इंजनों पर चलाए गए दस प्रश्न एक महीने के भीतर दिशा बताने के लिए पर्याप्त होते हैं। हम लॉग करते हैं कि किस इंजन ने हमें उद्धृत किया, सटीक प्रश्न क्या था, और प्रतिस्पर्धी स्रोत कौन थे। बार-बार दोहराया जाने वाला पैटर्न: जिन पृष्ठों को हमने निकालने की क्षमता के लिए फिर से लिखा वे दो से चार सप्ताह में उद्धरण पूल में आ गए, जबकि अछूते पृष्ठ ठहरे रहे।
पहले तकनीकी बुनियादी बातें पक्की करें
उद्धरण हिस्सेदारी के पीछे भागने से पहले, पुष्टि करें कि पृष्ठ पात्र भी है या नहीं। एक भटका हुआ noindex टैग, किसी 404 की ओर इशारा करता canonical, या कोई अवरुद्ध AI user-agent, सामग्री के महीनों के काम को मिटा देता है। इनका ऑडिट किसी अनुसूची पर करें, केवल लॉन्च से पहले नहीं। AI Readiness Checker crawl पहुँच और सामग्री संरचना का स्कोर साथ-साथ देता है, इसलिए किसी रिलीज़ से पहले चलाने के लिए यह सबसे तेज़ अकेली जाँच है।
कैनिबलाइज़ेशन पर नज़र रखें
यदि तीन पृष्ठ एक ही प्रश्न का थोड़ा-थोड़ा अलग उत्तर देते हैं, तो पुनर्प्राप्तिकर्ता को एक मज़बूत उत्तर के बजाय तीन आधे-प्रामाणिक उत्तर दिखते हैं, और मॉडल किसी का भी उद्धरण न देकर बचाव कर लेते हैं। ओवरलैप वाले पृष्ठों को एक प्रामाणिक उत्तर में समेकित करें। हमारे परखे हर पुनर्प्राप्ति सिस्टम में एक मज़बूत पृष्ठ तीन कमज़ोर पृष्ठों को मात देता है।
FAQ
क्या AEO, SEO की जगह ले रहा है?
नहीं। AEO, SEO का विस्तार करता है, उसकी जगह नहीं लेता। तकनीकी नींव (crawlability, साफ़ मेटाडेटा, तेज़ डिलीवरी, आंतरिक लिंक) वही काम है जिस पर दोनों विधाएँ निर्भर हैं। जो बदलता है वह है सामग्री परत: अब आप केवल रैंकिंग के लिए नहीं, निष्कर्षण और उद्धरण के लिए लिखते हैं। जो पृष्ठ अच्छी रैंक तो करता है पर अपना उत्तर छिपाता है, वह फिर भी उद्धरण हार जाएगा।
क्या AI सारांश वाकई मेरा ट्रैफ़िक घटाते हैं?
अक्सर हाँ, सूचनात्मक प्रश्नों के लिए। जब कोई Google AI सारांश दिखा, तब पारंपरिक परिणाम पर क्लिक दर 15% की तुलना में गिरकर 8% रह गई, और केवल 1% उपयोगकर्ताओं ने सारांश के भीतर किसी स्रोत लिंक पर क्लिक किया (Pew Research Center, 2025)। वाणिज्यिक और नेविगेशनल प्रश्न कम प्रभावित होते हैं, पर रुझान स्पष्ट है।
AEO बदलावों को उद्धरणों में दिखने में कितना समय लगता है?
हमारे अनुभव में, उन पृष्ठों पर निकालने की क्षमता के सुधार के लिए दो से चार सप्ताह जो पहले से crawl और अनुक्रमित हैं। चयन-पक्ष का लाभ, यानी GEO वाला हिस्सा, अधिक समय लेता है क्योंकि वह भरोसे के संकेत जमा होने पर निर्भर करता है। यांत्रिक सुधार तेज़ हैं। प्रतिष्ठा धीमी है। अपना रोडमैप ऐसे बनाएँ कि जल्दी मिलने वाली जीतें धैर्य वाले काम को सहारा दें।
क्या मुझे अपनी सामग्री की रक्षा के लिए AI crawlers को रोकना चाहिए?
केवल सोच-समझकर। GPTBot या PerplexityBot को रोकना आपको उस इंजन के उत्तरों से पूरी तरह हटा देता है, जो केवल गोपनीयता का नहीं, दृश्यता का फ़ैसला है। यदि आप उद्धरण तो चाहते हैं पर प्रशिक्षण में उपयोग नहीं, तो सामग्री-नीति नियंत्रण आपको पुनर्प्राप्ति की अनुमति देते हुए प्रशिक्षण पर रोक लगाने देते हैं। नियमों की हर तिमाही समीक्षा करें, क्योंकि 2023 के पुराने अवरोध चुपचाप दृश्यता की कीमत वसूलते रहते हैं।
आज मैं सबसे अधिक असर वाला कौन-सा एक बदलाव कर सकता हूँ?
अपने शीर्ष दस पृष्ठों की शुरुआत को फिर से लिखें ताकि हर अनुभाग अपना उत्तर पहले वाक्य में बता दे। यह सबसे सस्ती, सबसे तेज़ AEO जीत है, और यह सीधे खंड-स्तरीय पुनर्प्राप्ति को बेहतर करती है। परिणाम की पुष्टि Answer Extractability Checker से करें और जाँचें कि crawl पहुँच चुपचाप इन लाभों को नहीं रोक रही।
आगे क्या करें
उत्तर इंजन पहले से ही आपके पृष्ठ पढ़ रहे हैं। सवाल यह है कि उन्हें एक साफ़, उद्धरण योग्य उत्तर मिलता है या भूमिका भरे पाठ की दीवार। एक स्कोर किए गए ऑडिट से शुरू करें, तकनीकी बुनियादी बातें ठीक करें, फिर अपने सबसे मूल्यवान पृष्ठों को फिर से लिखें ताकि वे उत्तर से शुरू हों।
अपनी साइट को AI Readiness Checker से चलाएँ ताकि crawl पहुँच और सामग्री संरचना का स्कोर एक ही बार में मिल जाए। फिर इस समूह की दो सहयोगी मार्गदर्शिकाओं से और गहराई में जाएँ: पृष्ठ-दर-पृष्ठ पुनर्लेखन प्रक्रिया के लिए अपनी साइट को AI उद्धरणों के लिए कैसे अनुकूलित करें, और आगे आने वाली प्रोटोकॉल परत के लिए एजेंट की तैयारी।