O guia completo de Answer Engine Optimization (AEO) e GEO
A pesquisa já não é uma lista de links. Os motores de pesquisa de IA escrevem respostas diretas e visões gerais sintetizadas, e o tráfego vai para as páginas em que confiam o suficiente para citar. Se não construir o seu conteúdo para Answer Engine Optimization e Generative Engine Optimization, perde visibilidade na nova camada de pesquisa.
- Pesquisa de IA
- AEO
- SEO técnico
O que são motores de resposta e porque mudam o SEO?
Os motores de resposta leem as páginas por si e escrevem uma resposta sintetizada, por isso o clique que antes conquistava acontece agora dentro da caixa de resposta. A mudança é mensurável. Quando surgiu um resumo de IA do Google, os utilizadores clicaram num resultado tradicional em apenas 8% das visitas, contra 15% sem resumo (Pew Research Center, 2025).
Durante duas décadas o acordo foi simples. Escrevia uma pergunta, recebia dez links e fazia a leitura por si próprio. O motor recuperava documentos. Você sintetizava a resposta. Esse trabalho mudou de mãos.
Agora as AI Overviews da Google, o Perplexity e o ChatGPT Search leem várias páginas, resolvem contradições e escrevem eles próprios a resposta. O seu site torna-se uma citação no fundo, ou fica de fora. A escala é real: o ChatGPT ultrapassou os 800 milhões de utilizadores ativos semanais no final de 2025 (Fortune, 2025).
Este guia é o ponto central de tudo o que se segue. Cobre como funcionam os motores de resposta, o que torna uma página extraível, como são selecionadas as citações, o pipeline de recuperação que está por baixo de tudo e como medir se o seu trabalho está a dar frutos. Comece por passar o seu site pelo AI Readiness Checker para pontuar a posição em que está hoje.
Pontos-chave
- O AEO trata da extratibilidade (consegue um modelo retirar um facto limpo da sua página) e o GEO trata da seleção (confia em si o suficiente para o citar). Precisa de ambos.
- Quando surge um resumo de IA, a taxa de cliques no resultado tradicional cai para 8%, contra 15% sem resumo (Pew Research Center, 2025).
- Acrescentar citações, aspas e estatísticas pode aumentar a visibilidade de uma fonte nas respostas generativas até 40% (Aggarwal et al., KDD 2024).
- Escreva para o bloco, não para a página. Cada parágrafo é a unidade de recuperação, por isso tem de se sustentar sozinho.
- A quota de citações é volátil de mês para mês, por isso encare qualquer percentagem isolada como um instantâneo, não como uma referência.
Como o AEO difere do GEO
O AEO e o GEO são duas metades de um mesmo pipeline, não sinónimos. O AEO é o trabalho mecânico de tornar um facto extraível numa única passagem. O GEO é o trabalho de reputação de ser a fonte em que um modelo confia o suficiente para citar. Uma página pode ser perfeitamente extraível e ainda assim ser ignorada, por isso precisa de ambos, por esta ordem.
Pense nisto como ler e depois escolher. O recuperador tem de ler a sua página de forma limpa antes de o modelo o poder escolher em vez de um concorrente.
Answer Engine Optimization: extratibilidade
O Answer Engine Optimization faz uma única pergunta: consegue um modelo ler a sua página e retirar dela um facto limpo e citável? O SEO antigo recompensava introduções longas e aquecimentos narrativos. O AEO penaliza-os, porque o recuperador parte a sua página em blocos de algumas centenas de tokens e classifica cada bloco por si só. Um bloco que abre com “Antes de entrarmos nisto” perde para um bloco que abre com a resposta.
Este é um problema que pode resolver numa tarde. Audite a página, reescreva a introdução, reestruture os títulos, meça de novo. Trabalho mecânico, feedback rápido.
Generative Engine Optimization: seleção
O Generative Engine Optimization faz a pergunta mais difícil: depois de o recuperador ter obtido uma dúzia de páginas candidatas, em que factos confia o modelo? O GEO é o trabalho de ser a fonte que ele procura, não a que ignora. O estudo académico original que deu nome ao campo mostrou que os métodos de GEO (acrescentar citações, aspas e estatísticas) podem aumentar a visibilidade de uma fonte nas respostas generativas até 40% (Aggarwal et al., KDD 2024).
A seleção é mais lenta de conquistar. Um site totalmente novo com AEO impecável tem ainda de construir os sinais de confiança que o movem para o conjunto de citações de um modelo.
Cápsula de citação: o Answer Engine Optimization determina se um modelo consegue extrair um facto citável da sua página numa única passagem, enquanto o Generative Engine Optimization determina se o modelo confia em si o suficiente para o citar. Ambos importam: o estudo académico de GEO concluiu que estes métodos podem elevar a visibilidade de uma fonte até 40% (Aggarwal et al., KDD 2024).
Como funciona o pipeline de recuperação do motor de resposta?
Os motores de resposta executam um pipeline de cinco etapas: rastrear, indexar, recuperar, sintetizar, citar. Cada etapa filtra o que veio antes. Uma página que falha o rastreio nunca é indexada, e uma página que é indexada mas nunca recuperada nunca é citada. Perceber em que ponto fica pelo caminho indica-lhe exatamente o que corrigir primeiro.
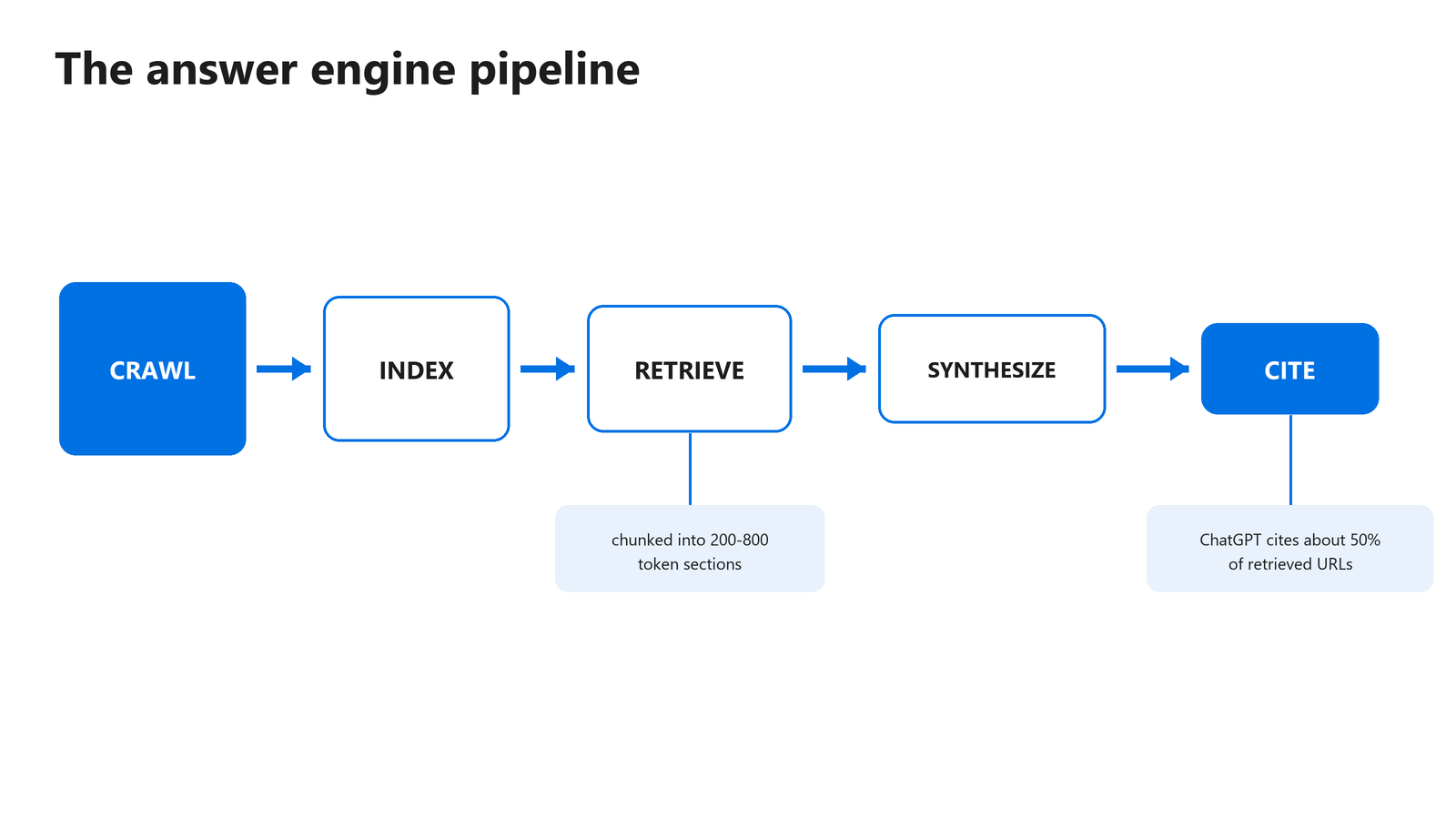
Figura 1: uma página tem de sobreviver a todas as etapas do pipeline antes de poder ser citada.
Rastreio e indexação
A etapa de rastreio é binária. Se bloquear o GPTBot, o ClaudeBot, o Google-Extended ou o PerplexityBot ao conteúdo público, exclui-se por completo das respostas desse motor. Uma vez rastreada, a sua página é analisada e armazenada. HTML limpo, entrega rápida e metadados precisos decidem todos a integralidade com que a página entra no índice.
É aqui que começa a maior parte da visibilidade perdida, e é também a etapa mais fácil de verificar. A lista de verificação completa para confirmar o acesso dos rastreadores de IA percorre os passos exatos.
Recuperação e síntese
A recuperação é onde acontece a divisão em blocos. O sistema parte a sua página em secções, transforma cada uma num vetor e associa as secções à pergunta do utilizador por semelhança. O modelo lê depois os blocos mais correspondentes e escreve uma resposta sintetizada. O seu parágrafo compete contra parágrafos de outros sites, não páginas inteiras contra páginas inteiras.
Nas auditorias que fazemos, a razão mais comum para uma página forte nunca aparecer é o seu melhor facto viver no parágrafo nove, depois de oito parágrafos de contextualização. O recuperador pontua os blocos iniciais, encontra enchimento e segue em frente.
Citar
A citação é a etapa de recompensa, e é seletiva. Uma análise de 1,4 milhões de prompts do ChatGPT concluiu que o modelo cita cerca de metade dos URL que recupera, com a taxa de citação fortemente ligada ao tipo de fonte (Ahrefs, 2025). Os resultados provenientes de pesquisa foram citados 88,46% das vezes. As páginas com slugs de URL em linguagem natural foram citadas 89,78% das vezes, contra 81,11% nos URL opacos.
O que torna o conteúdo extraível para a IA?
O conteúdo extraível enuncia a resposta primeiro, nomeia o seu assunto em cada parágrafo e concentra factos úteis num espaço pequeno. O recuperador pode ler apenas as duas primeiras frases de uma secção, por isso essas frases carregam o peso. A escrita densa e autossuficiente vence porque cada bloco é classificado isoladamente, sem o contexto que o resto da sua página fornece.
Enuncie a resposta primeiro
Coloque a resposta logo abaixo do título, antes de qualquer contexto. Se a pergunta for “qual é a capital de França”, a primeira frase é “A capital de França é Paris”. Os detalhes de apoio vêm a seguir. Os jornalistas chamaram a isto pirâmide invertida há um século, porque os editores cortavam as notícias de baixo para cima. A mesma lógica aplica-se agora aos blocos de recuperação.
Eis a diferença na prática. Uma abertura fraca esconde o facto:
Quando se trata de tags hreflang, há muitas coisas a considerar, e as boas práticas evoluíram ao longo dos anos.
Uma abertura forte começa por ele:
As tags hreflang dizem ao Google qual o idioma e a região que uma página alveja. Acrescente uma tag por região no head, incluindo uma tag de autorreferência.
A segunda versão é mais curta e contém três factos extraíveis. Teste as suas próprias páginas com o Answer Extractability Checker, que identifica com precisão os blocos que um extrator vai de facto retirar.
Escreva parágrafos autossuficientes
Cada parágrafo deve sobreviver a ser arrancado do contexto. Evite aberturas como “É eficaz porque” ou “Esta abordagem funciona bem quando”. Volte a nomear o assunto para que o parágrafo se sustente sozinho como resposta citável. Leia a sua página em voz alta, parágrafo a parágrafo. Se algum começar com um pronome que aponta para o parágrafo anterior, reescreva-o.
Corte o enchimento, mantenha o sinal
O enchimento dilui a densidade de sinal de cada bloco. Antes de publicar, passe o rascunho pelo AI Text Humanizer para eliminar as frases de aquecimento e expor as afirmações que sustentam o texto. Denso não significa prosa densa. Significa sinal denso: uma ideia por parágrafo, sem enchimento e com o facto enunciado de forma clara.
Cápsula de citação: o conteúdo extraível começa pela resposta, repete o assunto em cada parágrafo e sobrevive a ser retirado do contexto. Isto importa porque os sistemas de recuperação classificam cada bloco de forma independente, e o ChatGPT cita apenas cerca de metade dos URL que recupera (Ahrefs, 2025).
Como conquistar citações de IA?
Conquista citações combinando conteúdo extraível com sinais de confiança: cobertura tópica completa, afirmações seguras, factos fáceis de citar e validação externa. Quando o modelo escolhe, já leu uma dúzia de candidatos. A sua tarefa é ser a opção mais completa, mais citável e mais credível desse conjunto, não apenas uma opção correta.

Figura 2: a SERP clássica recompensa o posicionamento. O motor de resposta recompensa ser uma das poucas fontes citadas.
Cubra o tópico por completo
As páginas finas perdem para as abrangentes mesmo quando ambas contêm a resposta correta. Inclua os subtópicos, os termos e os factos de apoio que naturalmente andam juntos. O Topical Authority Mapper mostra onde a sua cobertura é fina, para que possa preencher as lacunas antes que um concorrente com uma página mais completa fique com a citação.
Enuncie os factos com confiança
A escrita cheia de ressalvas torna o conteúdo menos útil para um modelo que precisa de uma afirmação concreta. “Isto talvez tenda, em geral, a ser o caso” não dá nada ao modelo para citar. Onde souber a resposta, diga-a com clareza e depois liste as exceções à parte. Estatísticas, números de versão, datas e entidades nomeadas são todos fáceis de citar, por isso inclua-os.
Construa validação externa
A maioria das equipas trata a citação como um problema de conteúdo e fica por aí, mas a vantagem duradoura é reputacional. Os domínios que ganham citações de IA de forma consistente são aqueles que os modelos já veem referenciados noutros lugares. Um estudo de 13 semanas com 230 000 prompts e mais de 100 milhões de citações de IA concluiu que a Wikipedia e o Reddit lideram de forma consistente, enquanto a quota de cada domínio individual oscila muito de mês para mês (Semrush, 2025). A frequência de citação do Reddit no ChatGPT caiu de cerca de 60% para 10% entre o início de agosto e meados de setembro de 2025.
Antes de mais, passe as suas principais páginas comerciais pelo Citation Readiness Analyzer para ver se cada uma tem probabilidade de ser citada ou ignorada. Para o processo de reescrita página a página, veja como otimizar o seu site para citações de IA.
Formatar conteúdo para blocos de recuperação
Formate para o bloco, não para a página. Os sistemas de recuperação partem o texto em secções de cerca de 200 a 800 tokens e associam cada uma a uma pergunta de forma independente. Cada parágrafo é uma unidade de recuperação, por isso escreva de modo a que um parágrafo retirado da secção seis ainda responda bem a uma pergunta num contexto que o leitor nunca viu.
Use formatos densos
As listas e as tabelas concentram muitos detalhes úteis num espaço pequeno, o que ajuda quando um sistema retira apenas um bloco curto. Uma tabela comparativa de cinco linhas pode valer mil palavras de prosa, porque o recuperador pode citar a tabela inteira e o modelo pode resumir uma única linha. Os formatos densos são o conteúdo com mais sinal por token que pode escrever.
Use títulos em forma de pergunta e de correspondência exata
Não escreva títulos engenhosos. Se um utilizador quer reiniciar um router, escreva “Como reiniciar o router Netgear Nighthawk” e responda de imediato. A correspondência de padrões do título como pergunta é um dos sinais mais fortes que os recuperadores usam. Pesquise você mesmo a pergunta no Google, no ChatGPT e no Perplexity, repare na formulação exata que cada um apresenta e use a versão vencedora.
Torne o contexto interno explícito
As ligações internas dizem aos rastreadores como o seu site se encaixa, e acumulam-se. Cada novo artigo que liga à sua página-pilar aumenta a autoridade do pilar. Se publicar um hub sobre AEO, os seus artigos relacionados devem apontar para ele, e o hub deve apontar para eles. Essa estrutura também ajuda um modelo a perceber qual a página do seu site que é a resposta canónica para um tópico.
Cápsula de citação: os sistemas de recuperação partem as páginas em secções de 200 a 800 tokens e associam cada uma a uma consulta de forma independente, por isso cada parágrafo tem de se sustentar sozinho. As páginas com slugs de URL em linguagem natural foram citadas 89,78% das vezes, contra 81,11% nos URL opacos (Ahrefs, 2025).
Como medir o desempenho de AEO e GEO?
Mede o AEO e o GEO com quatro vias: saúde técnica, extratibilidade, cobertura tópica e quota de citações. Um relatório de posicionamento de palavras-chave já não conta a história toda, porque a métrica que mais importa é se o seu domínio aparece nas respostas de IA para as consultas que lhe interessam. O senão: a quota de citações é volátil, por isso encare cada leitura como um instantâneo.
Acompanhe a quota de citações como um instantâneo
A quota de citações é a frequência com que o seu domínio aparece nas AI Overviews, no ChatGPT, no Perplexity e nas respostas do Claude para as suas consultas-alvo. Os números mexem-se depressa. A Ahrefs mediu uma taxa de cliques 34,5% mais baixa na página mais bem posicionada quando uma AI Overview está presente, em 300 000 palavras-chave (Ahrefs, 2025). Um acompanhamento posterior relatou que o impacto tinha crescido ainda mais, e é exatamente por isso que se leem tendências, não números isolados.
Nas nossas verificações semanais por amostragem, dez consultas em três motores chegam para indicar a direção dentro de um mês. Registamos que motor nos citou, a consulta exata e as fontes concorrentes. O padrão que se repete: as páginas que reescrevemos para a extratibilidade entraram no conjunto de citações em duas a quatro semanas, enquanto as páginas intocadas ficaram estagnadas.
Fixe primeiro os fundamentos técnicos
Antes de perseguir a quota de citações, confirme que a página é sequer elegível. Uma tag noindex perdida, um canónico a apontar para um 404 ou um user-agent de IA bloqueado apagam meses de trabalho de conteúdo. Audite estes pontos de forma regular, não apenas antes do lançamento. O AI Readiness Checker pontua o acesso de rastreio e a estrutura de conteúdo em conjunto, por isso é a verificação isolada mais rápida de executar antes de uma publicação.
Atenção à canibalização
Se três páginas respondem à mesma pergunta de formas ligeiramente diferentes, o recuperador vê três respostas meio autoritativas em vez de uma forte, e os modelos protegem-se não citando nenhuma. Consolide as páginas sobrepostas numa única resposta canónica. Uma página forte vence três fracas em todos os sistemas de recuperação que testámos.
Perguntas frequentes
O AEO está a substituir o SEO?
Não. O AEO estende o SEO, não o substitui. A base técnica (rastreabilidade, metadados limpos, entrega rápida, ligações internas) é o mesmo trabalho do qual ambas as disciplinas dependem. O que muda é a camada de conteúdo: agora escreve para a extração e a citação, não apenas para o posicionamento. Uma página que se posiciona bem mas esconde a sua resposta continua a perder a citação.
Os resumos de IA reduzem mesmo o meu tráfego?
Muitas vezes sim, nas consultas informativas. Quando surgiu um resumo de IA do Google, a taxa de cliques no resultado tradicional caiu para 8%, contra 15% sem resumo, e apenas 1% dos utilizadores clicou numa ligação de fonte dentro do próprio resumo (Pew Research Center, 2025). As consultas comerciais e de navegação são menos afetadas, mas a tendência é clara.
Quanto tempo até as mudanças de AEO aparecerem nas citações?
Pela nossa experiência, duas a quatro semanas para correções de extratibilidade em páginas que já estão rastreadas e indexadas. Os ganhos do lado da seleção, a metade do GEO, demoram mais porque dependem da acumulação de sinais de confiança. As correções mecânicas são rápidas. A reputação é lenta. Planeie o seu roadmap para que as vitórias rápidas financiem o trabalho paciente.
Devo bloquear os rastreadores de IA para proteger o meu conteúdo?
Só com intenção. Bloquear o GPTBot ou o PerplexityBot remove-o por completo das respostas desse motor, o que é uma decisão de visibilidade, não apenas de privacidade. Se quer citações mas não uso para treino, os controlos de política de conteúdo permitem autorizar a recuperação enquanto restringe o treino. Reveja as regras trimestralmente, porque bloqueios obsoletos de 2023 custam visibilidade em silêncio.
Qual é a mudança de maior impacto que posso fazer hoje?
Reescreva a abertura das suas dez principais páginas para que cada secção enuncie a sua resposta na primeira frase. Esta é a vitória de AEO mais barata e rápida, e melhora diretamente a recuperação ao nível do bloco. Confirme o resultado com o Answer Extractability Checker e verifique que o acesso de rastreio não está a bloquear os ganhos em silêncio.
O que fazer a seguir
Os motores de resposta já estão a ler as suas páginas. A questão é se encontram uma resposta limpa e citável ou uma parede de texto de aquecimento. Comece com uma auditoria pontuada, corrija os fundamentos técnicos e depois reescreva as suas páginas de maior valor para começarem pela resposta.
Passe o seu site pelo AI Readiness Checker para pontuar o acesso de rastreio e a estrutura de conteúdo numa única passagem. Depois aprofunde com os dois guias irmãos deste conjunto: como otimizar o seu site para citações de IA para o processo de reescrita página a página, e preparação para agentes para a camada de protocolo que chega a seguir.